前言 当一个App发布之后,突然发现了一个严重bug需要进行紧急修复,这时候公司各方就会忙得焦头烂额:重新打包App、测试、向各个应用市场和渠道换包、提示用户升级、用户下载、覆盖安装。有时候仅仅是为了修改了一行代码,也要付出巨大的成本进行换包和重新发布。
这时候就提出一个问题:有没有办法以补丁的方式动态修复紧急Bug,不再需要重新发布App,不再需要用户重新下载,覆盖安装?
虽然Android系统并没有提供这个技术,但是很幸运的告诉大家,答案是:可以,热补丁动态修复技术可以解决以上这些问题。
对于热修复方案,当前市场有四种解决方案,分别是 Xposed、AndFix、ClassLoader、Proxy/Delegate。前两个是阿里开源的框架,第三个是QQ空间团队想出的对策。在我看来,前两个方案的思路是极其相似的,都是想要通过指针替换掉出Bug的方法、类,不同的是Xposed将需要替换的方法连接到hookedMethodCallback,以他来实现替换后方法的调配,而AndFix就比较简洁粗暴了,直接就是获取需要替换的方法指针,将指针指向修改之后的新的java代码;相比之下,ClassLoader方案便较为巧妙的多了,他巧妙利用了BaseDexClassLoader的机制,类似于dex分包技术。Proxy/Delegate的方案则是使用ProxyApplication动态加载主程序dex。
目录
Xposed
AndFix
ClassLoader
基于Proxy/Delegate
四种方案的比较
基于以上四种方案的开源框架以及比较
一、Xposed 大体上的原理是:
1、首先,我们来理解一个概念——Zygote进程。
在Android系统中,每一个应用程序都是由Zygote进程进行孵化出来的。Zygote进程是由init进程创建而成。Zygote在启动时候,创建了一个Davlik虚拟机实例,每当Zygote进程创建孵化出一个应用程序进程时,都会将这个Daclik虚拟机实例进行拷贝一份,拷贝到新创建的应用程序进程之中,从而使得每一个应用程序进程都有一个独立的Dalvik虚拟机实例。
这样看来,Zygote进程就犹如一个盛产的孕妇,每生产一个孩子,也就是应用程序进程,都会给孩子先打疫苗(拷贝一份Davlik虚拟机实例到应用程序之中),让孩子们能够正常的健康成长。
Zygote进程在启动的过程中,除了会创建一个Dalvik虚拟机实例之外,还会将Java运行时库加载到进程中来,以及注册一些Android核心类的JNI方法来前面创建的Dalvik虚拟机实例中去。注意,一个应用程序进程被Zygote进程孵化出来的时候,不仅会获得Zygote进程中的Dalvik虚拟机实例拷贝,还会与Zygote一起共享Java运行时库。这也就是可以将XposedBridge这个jar包(Xposed的关键jar包)加载到每一个Android应用程序中的原因。XposedBridge有一个私有的Native方法hookMethodNative,这个方法也在app_process中使用。这个函数提供一个方法对象利用Java的Reflection机制来对内置方法覆写。
2、接着,我们再来看看Xposed的关键思想Hook。
Hook的中文翻译是,挂钩、钓钩,比较形象。那么它要用来钓哪一条鱼的呢?根据不同的鱼,我们以便准备不同的鱼饵。
所以,在Android系统启动时候Zygote进程加载的XposedBridge jar包,就有了用武之地。在XposedBridge之中有一个私有的方法——hookMethodNative,它将一个方法作为输入参数并且改变Dalvik虚拟机中对于该方法的定义。它将该方法的类型改变为native并且将这个方法的实现链接到它的本地的通用类的方法。
在hookMethodNative的实现中,会调用XposedBridge中的handleHookedMethod这个方法来传递参数。而这个方法,我们可以称之为鱼竿。它将一个方法对象,也就是我们需要替换的方法或者类,作为输入参数,当然,你可以使用java的反射几只来获取这个方法,不过,这个方法对象,这个输入参数就是我们说的“鱼饵”了,根据鱼饵,我们使用鱼竿,便可以钓起我们想要钓起的大鱼。而大鱼便是所要hook的方法对象Method的指针。得到所需要替换的Method指针之后,因为我们的目的是要替换有bug的方法。所以,我们将得到的指针链接到hookedMethodCallback上面去,并设置该Method指向替换成为的方法,以便hookedMethodCallback可以获取真正期望执行的java方法。
现在所有被hook的方法,都指向了hookedMethodCallback的c方法中,然后在此方法中实现调用替换成为的java方法。
handleHookedMethod这个方法类似于一个统一调度的Dispatch任务分派例程,其对应的底层的C++函数是xposedCallHandler。而handleHookedMethod实现里面会根据一个全局结构hookedMethodCallbacks来选择相应的hook函数,并调用他们的before, after函数。
那么,hook的具体过程是:
1、首先通过DexClassloader(这个会在ClassLoader部分具体说明)来加载所要hook的方法,分析类后,进c++层,拿到要hook的Method类,然后在handleHookedMethod中,通过dvmslotTomethod方法获取所要替换的Method*指针。
1 Method* method = dvmSlotToMethod(declaredClass, slot);
declaredClass就是所hook方法所在的类,对应的object。slot是Method类中,描述此java对象在vm中的索引;那么通过这个方法,我们就获取了c层的Method指针
2、将该方法标记为一个native方法
1 SET_METHOD_FLAG (method, ACC_NATIVE );
3、重定向该方法到hookedMethodCallback,这样当被hook的java方法执行时,就会调到c层的hookedMethodCallback方法。通过meth->nativeFunc重定向MethodCallBridge到hookedMethodCallback这个方法上,控制这个c++指针是无视java的private的。
1 method->nativeFunc = &hookedMethodCallback;
另外,在method结构体中有
1 method->insns = (const u2*) hookInfo;
用insns指向替换成为的方法,以便hookedMethodCallback可以获取真正期望执行的java方法。
3、优点
1)无需重启就可以达到修复bug的目的
2)多个模块可同时进行安装
3)无需修改任何的APK
4、缺点
1)需要Android 的root权限
2)Dexposed不支持Art模式(5.0+),且写补丁有点困难,需要反射写混淆后的代码,粒度太细,要替换的方法多的话,工作量会比较大。
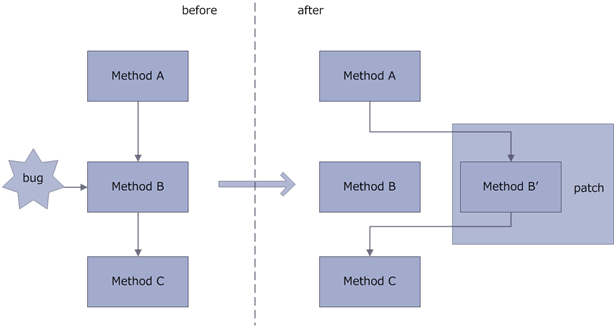
二、AndFix 1、AndFix的原理就是方法的替换,把有bug的方法替换成补丁文件中的方法。
注:在Native层使用指针替换的方式替换bug方法,以达到修复bug的目的。
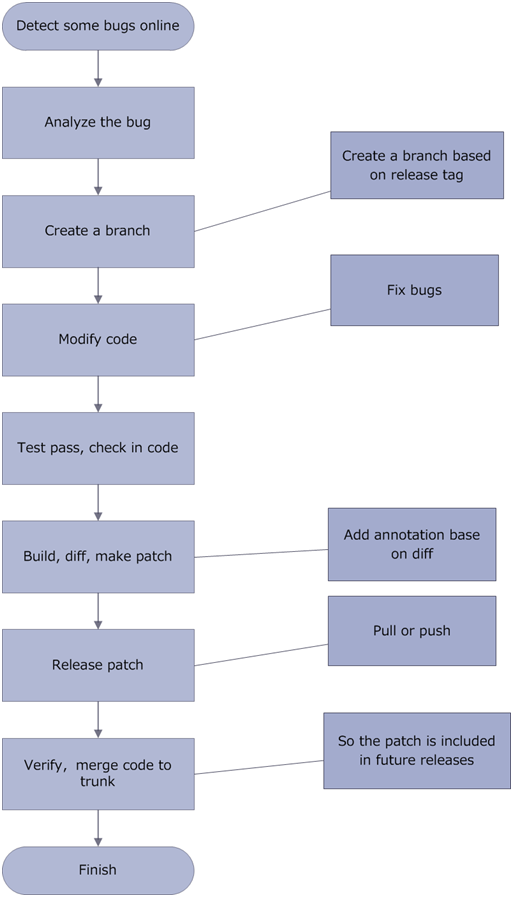
使用AndFix修复热修复的整体流程:
AndFix,我觉得是阿里开源的自动化程度比较高的热修复框架了。因为你发现,框架、工具已经可以做到帮你查找修改前修改后类的不同,并能够将之打包成为对应的补丁。开发人员所要负责的不过是对于Bug的修改而已。
修复补丁的具体过程是:
1)我们及时修复好bug之后,我们可以apkpatch工具将两个apk做一次对比,然后找出不同的部分。可以看到生成的apatch了文件。若果这个时候,我们把后缀改成zip再解压开,里面有一个dex文件。反编译之后查看一下源码,里面就是被修复的代码所在的类文件,这些更改过的类都加上了一个_CF的后缀,并且变动的方法都被加上了一个叫@MethodReplace的annotation,通过clazz和method指定了需要替换的方法。
2)客户端得到补丁文件后就会根据annotation来寻找需要替换的方法。从AndFixManager.fix方法开始,客户端找到对应的需要替换的方法,然后在fix方法的具体实现中调用fixClass方法进行方法替换过程。
3)由JNI层完成方法的替换。fixClass方法遍历补丁class里的方法,在jni层对所需要替换的方法进行一一替换。关键代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private void replaceMethod(ClassLoader classLoader, String clz, String meth, Method method) { try { String key = clz + "@" + classLoader.toString(); Class<?> clazz = mFixedClass.get(key); if (clazz == null) {// class not load // 要被替换的class Class<?> clzz = classLoader.loadClass(clz); / / 这里也很黑科技,通过C层,改写accessFlags,把需要替换的类的所有方法(Field)改成了public,具体可以看Method结构体 clazz = AndFix.initTargetClass(clzz); } if (clazz != null) {/ / initialize class OK mFixedClass.put(key, clazz); / / 需要被替换的函数 Method src = clazz.getDeclaredMethod(meth, method.getParameterTypes()); / / 这里是调用了jni,art和dalvik分别执行不同的替换逻辑,在cpp进行实现 AndFix.addReplaceMethod(src, method); } } catch (Exception e) { Log.e(TAG, "replaceMethod", e); } }
2、优点
1)可以多次打补丁。如果本地保存了多个补丁,那么AndFix会按照补丁生成的时间顺序加载补丁。具体是根据.apatch文件中的PATCH.MF的字段Created-Time。
2)安全性
readme提示开发者需要验证下载过来的apatch文件的签名是否就是在使用apkpatch工具时使用的签名,如果不验证那么任何人都可以制作自己的apatch文件来对你的APP进行修改。
3)不需要重启APP即可应用补丁。
3、缺点
1)不支持YunOS
三、ClassLoader 其实我更希望将之称之为MutilDex方案,因为他是基于谷歌的MutilDex项目思想而来,dex拆分是其核心。
1、ClassLoader的原理
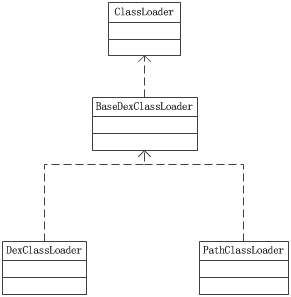
首先,在说到这个方案的原理的时候,我们需要先了解一下Android的ClassLoader体系
由上图可以看出,在叶子节点上,我们能使用到的是DexClassLoader和PathClassLoader,这也是Android中加载类一般使用到的。
首先看下这两个类的区别:
对于PathClassLoader,从文档上的注释来看:
Provides a simple {@link ClassLoader} implementation that operates on a list of files and directories in the local file system, but does not attempt to load classes from the network. Android uses this class for its system class loader and for its application class loader(s).
Android是使用这个类作为其系统类和应用类的加载器,只能去加载已经安装到Android系统中的apk文件。
对于DexClassLoader,依然看下注释:
A class loader that loads classes from {@code .jar} and {@code .apk} files containing a {@code classes.dex} entry. This can be used to execute code not installed as part of an application.
可以用来从.jar和.apk类型的文件内部加载classes、dex文件。可以用来执行非安装的程序代码。Android应用就是用它来加载;
那这两个ClassLoader有与我们的热修复有什么联系?
好吧,我们先来看看代码吧:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 //BaseDexClassLoader: @Override protected Class< ?> findClass(String name) throws ClassNotFoundException { List<Throwable> suppressedExceptions = new ArrayList<Throwable>(); Class c = pathList.findClass(name, suppressedExceptions); if (c == null) { ClassNotFoundException cnfe = new ClassNotFoundException("Didn't find class \"" + name + "\" on path: " + pathList); for (Throwable t : suppressedExceptions) { cnfe.addSuppressed(t); } throw cnfe; } return c; }
由上述函数可知,当我们需要加载一个class时,实际是从pathList中去需要的,查阅源码,发现pathList是DexPathList类的一个实例。好,接着去分析DexPathList类中的findClass函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public Class findClass(String name, List<Throwable> suppressed) { for (Element element : dexElements) { DexFile dex = element.dexFile; if (dex != null) { Class clazz = dex.loadClassBinaryName(name, definingContext, suppressed); if (clazz != null) { return clazz; } } } if (dexElementsSuppressedExceptions != null) { suppressed.addAll(Arrays.asList(dexElementsSuppressedExceptions)); } return null; }
那么我们开始有点头绪了。我们在使用类的时候,会让PathClassLoader或者DexClassLoader对该类进行类加载。而加载的过程就是,遍历一个装在dex文件(每个dex文件实际上是一个DexFile对象)的数组(Element数组,Element是一个内部类),然后依次去加载所需要的class文件,直到找到为止。
BaseDexClassLoader中有个pathList对象,pathList中包含一个DexFile的集合dexElements,而对于类加载,就是遍历这个集合,通过DexFile去寻找。一个ClassLoader可以包含多个dex文件,每个dex文件是一个Element,多个dex文件排列成一个有序的数组dexElements,当找类的时候,会按顺序遍历dex文件,然后从当前遍历的dex文件中找类,如果找类则返回,如果找不到从下一个dex文件继续查找。
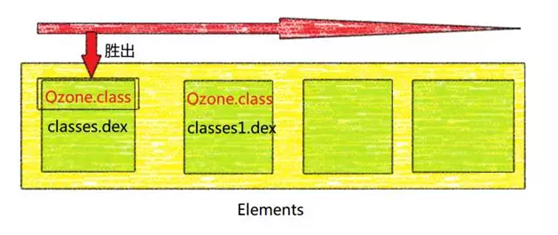
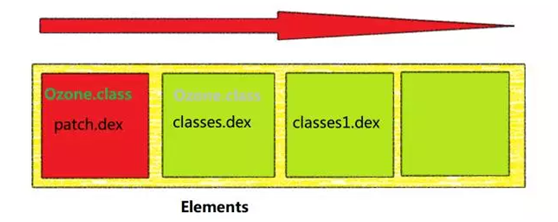
而这里面就正好让我们有机可乘。对,也就是理论上,如果在不同的dex中有相同的类存在,那么会优先选择排在前面的dex文件的类,如下图:
在此基础上,我们觉得可以用来作为热补丁的方案。把有问题的类打包到一个dex(patch.dex)中去,然后把这个dex插入到Elements的最前面,这样,在类加载的过程中便会优先加载补丁包中dex的类,如下图:
嗯,原理大致就是这样。
但是,在实现过程中,我们还会遇到一个CLASS_ISPREVERIFIED问题。
什么是CLASS_ISPREVERIFIED问题?
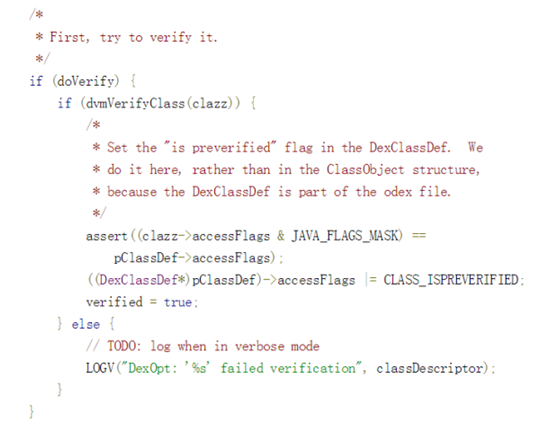
首先我们来看看一下代码:
这段代码是dex转化成odex(dexopt)的代码中的一段,我们知道当一个apk在安装的时候,apk中的classes.dex会被虚拟机(dexopt)优化成odex文件,然后才会拿去执行。
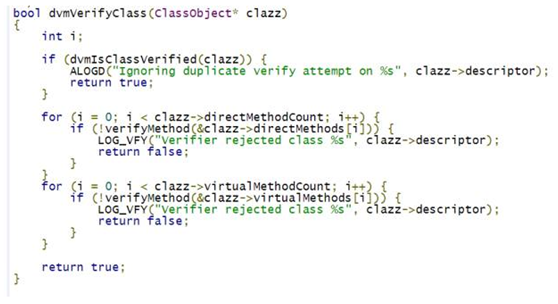
虚拟机在启动的时候,会有许多的启动参数,其中一项就是verify选项,当verify选项被打开的时候,上面doVerify变量为true,那么就会执行dvmVerifyClass进行类的校验,如果dvmVerifyClass校验类成功,那么这个类会被打上CLASS_ISPREVERIFIED的标志。这样看来,打上CLASS_ISPREVERIFIED其实是Android的一种性能优化方式。
那么具体的校验过程是什么样子的呢?
概括一下就是如果以上方法中直接引用到的类(第一层级关系,不会进行递归搜索)和clazz都在同一个dex中的话,那么这个类就会被打上CLASS_ISPREVERIFIED。
而被打上CLASS_ISPREVERIFIED之后,在ClassLoader加载与需要修改类相关的相关类时候,却发现他们两个却不是来自于同一个dex的,这个时候就会抛出异常了。
所以我们接下要做的就是阻止相关类被打上CLASS_ISPREVERIFIED标记。
一般采用的方案是往所有类的构造函数里面插入了一段代码,代码如下:
1 2 3 if (ClassVerifier.PREVENT_VERIFY ) { System.out.println(AntilazyLoad.class );// 需要修改的类 }
这样,需要与修改的类以及其相关类,在进行校验的时候,因为修改后的类所在的dex与原来的dex不同,也就是与相关类的dex不同,这样,他们就不会被打上CLASS_ISPREVERIFIED了。
为了实现以上操作,QQ空间采用了javassist动态代码注入。用javassist将这个类在编译打包的过程中插入到目标类中。
大致的流程是:在dx工具执行之前,将LoadBugClass.class文件呢,进行修改,再其构造中添加System.out.println(dodola.hackdex.AntilazyLoad.class),然后继续打包的流程。注意:AntilazyLoad.class这个类是独立在hack.dex中。
总结下,其实我们需要做的就是两件事:
1、动态改变BaseDexClassLoader对象间接引用的dexElements;
2、在app打包的时候,阻止相关类去打上CLASS_ISPREVERIFIED标志。所有与该类相关的类都需要进行动态注入,可进行修改,也是需要进行fix的对象。
四、基于Proxy/Delegate 当项目有加壳子,插件化或热修复等需求的时候,可以使用Proxy/Delegate Application框架的方式。
在正常的模式中,一个程序一般只有一个Application入口,而Proxy/Delegate模式中需要有两个Application,原程序的Application改为Delegate Application,再新加一个Proxy Application,由Proxy Application 提供一系列的个性化定制,再将所有的context和context相关的引用全部转化为Delegate Application的实例,让外界包括Delegate Application自身都以为该App的Application入口就是Delegate Application.
采用的是Proxy/Delegate Application框架。
主要实现的流程:
1、替换主程序dex文件为代理启动程序的dex文件
2、代理启动程序启动后,动态加载主程序dex
3、ProxyApplication替换消除本身Context引用为MyApplication
4、启动主程序的Application.
经过上述的步骤处理,由于程序启动dex只是一个代理,而主程序的dex是动态加载的,所以就可以达到不升级主程序不更改版本号只升级dex文件来修复线上紧急bug的目的.
五、四种方案的比较
Xposed方法生成补丁难度较大,需要反射写混淆后的代码,粒度太细,如果替换方法很多的话,工作量巨大。
AndFix支持2.3 - 6.0系统,但JNI不像JAVA那样标准,所以偶尔会有未知的机型异常。从实现来说,类似Xposed,通过JNI来替代方法,更加简洁的完成补丁修复,应用PATCH不需要重启。但由于实现上直接跳过了类初始化,设置为初始化完毕,所以静态函数、静态成员、构造函数都会出现问题,复杂的类Class.forName很可能直接崩溃。
ClassLoader方案支持2.3 - 6.0系统,对启动速度会有略微影响,而且只能下次启动生效。
Proxy/Delegate方案,对于dex的要求比较高,如果DEx文件较为庞大,启动速度会变慢。
相比而言,ClassLoader方案较为可靠,但是如果Dex文件较为庞大,启动速度会变慢;而AndFix则适用于应用不重启即可修复,且方法够简单;Xposed方案较为复杂,暂不考虑。
六、基于以上四种方案的开源框架以及比较 1、Dexpost:
1)原理:在底层虚拟机运行时hoop方法;
2)缺点:适配方面存在一些问题,目前不支持android6.0,5,1;art运行时;
3)优点:无需重启就可以达到修复bug的目的;
2、AndFix:
1)原理:在Native层使用指针替换的方法替换bug方法,达到修复bug的目的;
2)缺点:
底层替换,稳定性方面可能需要实际检测;
不支持YunOS;
无法添加新类和新的字段;
需要使用加固前的apk制作补丁,但是补丁文件很容易被反编译,也就是修改过的类源码容易泄露;
使用加固平台可能会使热补丁功能失效;
无法添加类和字段;
3)优点:无需中期就可以达到修复bug的目的;
3、HotFix:
1)原理:通过替换类加载器中bugclass,达到修复bug的目的;
2)缺点:需要重新启动才可以修复bug;
3)优点:java运行层修复,稳定性较好;
4、Nuwa:
1)原理:通过替换类加载器中bugclass,达到修复bug的目的;
2)缺点:需要重新启动才可以修复bug;
3)优点:java运行层修复,稳定性较好;自动化热修复
5、DroidFix:
1)原理:通过替换类加载器中bugclass,达到修复bug的目的;
2)缺点:需要重新启动才可以修复bug;
3)优点:java运行层修复,稳定性较好;
6、dynamic-load-apk
1)缺点:不支持Service和BroadcastReceiver;迁移成本高,需要修改插件,插件app需要继承自proxyActivity
2)优点: 插件无需安装host即可吊起;支持R访问插件资源;插件支持Activity和FragmentActivity;基本无反射调用;插件安装后任可独立运行
7、Droid Plugin
1)缺点:无法使用自定义资源的通知;法注册一些特殊Intent Filter的组件(四大组件);对Native支持不好
2)优点:插件无需任何修改,可独立安装运行,也可以做插件运行;四大组件无需在Host程序注册;超强隔离性,不同插件运行在不同的进程中;资源完全隔离;实现进程管理,插件的空进程会被及时回收,占用内存低;插件的静态广播会被当作动态处理,如果插件没有运行,静态广播永远不会触发;API侵入性低
8、DynamicAPK
1)优点:
更加有利于并发开发;
提升编译速度;
提升启动速度。
2)缺点:
dex解压、dexopt、加载耗时较长,使用按需加载启动时间过长