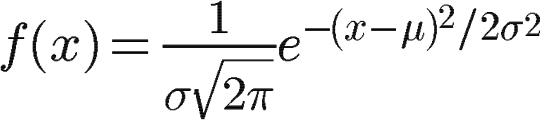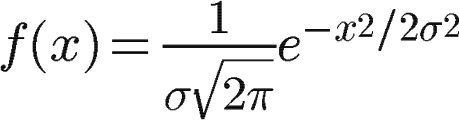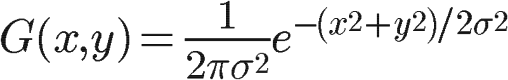前言
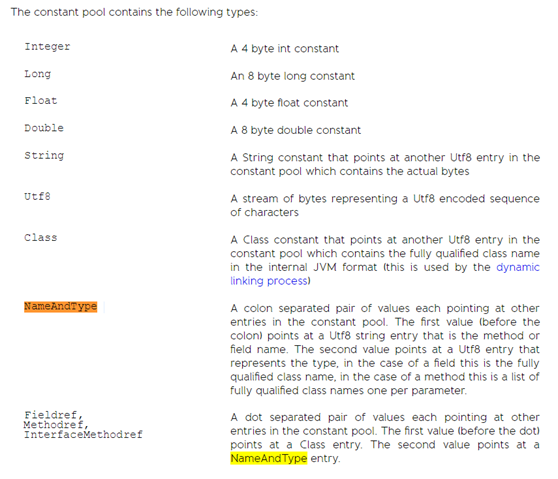
| 访问控制 | private | protected | public |
| 类,方法和变量修饰符 | abstract | class | extends | final | implements | interface | native |
| | new | static | strictfp | synchronized | transient | volatile |
| 程序控制 | break | continue | return | do | while | if | else |
| | for | instanceof | switch | case | default |
| 错误处理 | try | catch | throw | throws | finally |
| 包相关 | import | package |
| 基本类型 | boolean | byte | char | double | float | int | long |
| | short | null | true | false |
| 变量引用 | super | this | void |
| 保留字 | goto | const |
详细解释
1、访问控制
- private 私有的
private 关键字是访问控制修饰符,可以应用于类、方法或字段(在类中声明的变量)。 只能在声明 private(内部)类、方法或字段的类中引用这些类、方法或字段。在类的外部或者对于子类而言,它们是不可见的。
- protected 受保护的
protected 关键字是可以应用于类、方法或字段(在类中声明的变量)的访问控制修饰符。可以在声明 protected 类、方法或字段的类、同一个包中的其他任何类以及任何子类(无论子类是在哪个包中声明的)中引用这些类、方法或字段。
- public 公共的
public 关键字是可以应用于类、方法或字段(在类中声明的变量)的访问控制修饰符。 可能只会在其他任何类或包中引用 public 类、方法或字段。
那么我们总结一下,Java之中的权限访问修饰符(其实还有一种权限访问情况,就是默认情况,暂且称作default吧):
| 访问权限 | 当前类 | 包 | 子类 | 其他包 |
| public | ∨ | ∨ | ∨ | ∨ |
| protect | ∨ | ∨ | ∨ | × |
| default | ∨ | ∨ | × | × |
| private | ∨ | × | × | × |
2、类、方法和变量修饰符
- abstract 声明抽象
abstract关键字可以修改类或方法。abstract类可以扩展(增加子类),但不能直接实例化。abstract方法不在声明它的类中实现,但必须在某个子类中重写。采用 abstract方法的类本来就是抽象类,并且必须声明为abstract。
- class类
class 关键字用来声明新的 Java 类,该类是相关变量和/或方法的集合。类是面向对象的程序设计方法的基本构造单位。类通常代表某种实际实体,如几何形状或人。类是对象的模板。每个对象都是类的一个实例。要使用类,通常使用 new 操作符将类的对象实例化,然后调用类的方法来访问类的功能。
- extends 继承、扩展
extends 关键字用在 class 或 interface 声明中,用于指示所声明的类或接口是其名称后跟有 extends 关键字的类或接口的子类。子类继承父类的所有 public 和 protected 变量和方法(但是不包括构造函数)。 子类可以重写父类的任何非 final 方法。一个类只能扩展一个其他类。
extends 关键字用在 class 或 interface 声明中,用于指示所声明的类或接口是其名称后跟有 extends 关键字的类或接口的子类。
- final 最终、不可改变
在Java中,final关键字可以用来修饰类、方法和变量(包括成员变量和局部变量)。final方法在编译阶段绑定,称为静态绑定(static binding)。下面就从这四个方面来了解一下final关键字的基本用法。
1、修饰类
当用final修饰一个类时,表明这个类不能被继承,不能有子类。也就是说,如果一个类你永远不会让他被继承,就可以用final进行修饰。final类中的成员变量可以根据需要设为final,但是要注意final类中的所有成员方法都会被隐式地指定为final方法。
2、修饰方法
下面这段话摘自《Java编程思想》:
使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升。在最近的Java版本中,不需要使用final方法进行这些优化了。
因此,如果只有在想明确禁止 该方法在子类中被覆盖的情况下才将方法设置为final的。
还有就是,类的private方法会隐式地被指定为final方法。
3、修饰变量
修饰变量是final用得最多的地方。
对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。引用变量被final修饰之后,虽然不能再指向其他对象,但是它指向的对象的内容是可变的。
4、final参数
当函数参数为final类型时,你可以读取使用该参数,但是无法改变该参数的值或者引用指向。道理同final变量。
概括起来就是:
在A类是声明为final类型的方法,那么不能在子类里被覆盖;
如果A类被声明为final类型的类,那么B类不能继承A类;
如果成员变量声明为final类型,那么成员变量不能被修改;
注意:
1、一个类不能同时是 abstract 又是 final。abstract 意味着必须扩展类,final 意味着不能扩展类。一个方法不能同时是 abstract 又是 final。abstract 意味着必须重写方法,final 意味着不能重写方法。两者是相互矛盾的。
2、当用final作用于类的成员变量时,成员变量(注意是类的成员变量,局部变量只需要保证在使用之前被初始化赋值即可)必须在定义时或者构造器中进行初始化赋值,而且final变量一旦被初始化赋值之后,就不能再被赋值了。
3、final变量和普通变量的区别。当final变量是基本数据类型以及String类型时,如果在编译期间能知道它的确切值,则编译器会进行优化,会把它当做编译期常量使用。也就是说在用到该final变量的地方,相当于直接访问的这个常量,不需要在运行时确定。这种和C语言中的宏替换有点像。而普通变量在编译时,确定不了自身的值,需要在运行时才能知道。
4、局部内部类和匿名内部类只能访问局部final变量。因为这里的局部变量,需要在编译阶段便需要确定下来的。也就是说,如果局部变量的值在编译期间就可以确定,则直接在匿名内部里面创建一个拷贝。如果局部变量的值无法在编译期间确定,则通过构造器传参的方式来对拷贝进行初始化赋值。
- implements实现
implements 关键字在 class 声明中使用,以指示所声明的类提供了在 implements 关键字后面的名称所指定的接口中所声明的所有方法的实现。类必须提供在接口中所声明的所有方法的实现。一个类可以实现多个接口。
- interface 接口
interface 关键字用来声明新的 Java 接口,接口是方法的集合。
接口是 Java 语言的一项强大功能。任何类都可声明它实现一个或多个接口,这意味着它实现了在这些接口中所定义的所有方法。
实现了接口的任何类都必须提供在该接口中的所有方法的实现。一个类可以实现多个接口。
- native 本地
native 关键字可以应用于方法,以指示该方法是用Java以外的语言实现的,方法对应的实现不是在当前文件,而是在用其他语言(如C和C++)实现的文件中。。
Java不是完美的,Java的不足除了体现在运行速度上要比传统的C++慢许多之外,Java无法直接访问到操作系统底层(如系统硬件等),为此Java使用native方法来扩展Java程序的功能。
可以将native方法比作Java程序同C程序的接口,其实现步骤:
1、在Java中声明native()方法,然后编译;
2、用javah产生一个.h文件;
3、写一个.cpp文件实现native导出方法,其中需要包含第二步产生的.h文件(注意其中又包含了JDK带的jni.h文件);
4、将第三步的.cpp文件编译成动态链接库文件;
5、在Java中用System.loadLibrary()方法加载第四步产生的动态链接库文件,这个native()方法就可以在Java中被访问了。
JAVA本地方法适用的情况
1、为了使用底层的主机平台的某个特性,而这个特性不能通过JAVA API访问
2、为了访问一个老的系统或者使用一个已有的库,而这个系统或这个库不是用JAVA编写的
3、为了加快程序的性能,而将一段时间敏感的代码作为本地方法实现。
- new 新,创建
new 关键字用于创建类的新实例。
new 关键字后面的参数必须是类名,并且类名的后面必须是一组构造方法参数(必须带括号)。
参数集合必须与类的构造方法的签名匹配。
= 赋值号左侧的变量的类型必须与要实例化的类或接口具有赋值兼容关系。
- static 静态
static可以用于修饰属性,可以修饰代码块,也可以用于修饰方法,还可以用于修饰类。
1、static修饰属性:无论一个类生成了多少个对象,所有这些对象共同使用唯一一份静态的成员变量;一个对象对该静态成员变量进行了修改,其他对象的该静态成员变量的值也会随之发生变化。如果一个成员变量是static的,那么我们可以通过‘类名.成员变量名’的方式来使用它。
2、static修饰方法:static修饰的方法叫做静态方法。对于静态方法来说,可以使用‘类名.方法名’的方式来访问。静态方法只能继承,不能重写(Override),因为重写是用于表现多态的,重写只能适用于实例方法,而静态方法是可以不生成实例直接用类名来调用,这就会与重写的定义所冲突,与多态所冲突,所以静态方法不能重写,只能是隐藏。
static方法与非static方法:不能在静态方法中访问非静态成员变量;可以在静态方法中访问静态的成员变量。可以在非静态方法中访问静态的成员变量:因为静态方法可以直接用类名来调用,而非静态成员变量是在创建对象实例时才为变量分配内存和初始化变量值。
不能在静态方法中使用this关键字:因为静态方法可以直接用类名来调用,而this实际上是创建实例时,实例对应的一个应用,所以不能在静态方法上使用this。
3、static修饰代码块:静态代码块。静态代码块的作用也是完成一些初始化工作。首先执行静态代码块,然后执行构造方法。静态代码块在类被加载的时候执行,而构造方法是在生成对象的时候执行;要想调用某个类来生成对象,首先需要将类加载到Java虚拟机上(JVM),然后由JVM加载这个类来生成对象。
类的静态代码块只会执行一次,是在类被加载的时候执行的,因为每个类只会被加载一次,所以静态代码块也只会被执行一次;而构造方法则不然,每次生成一个对象的时候都会调用类的构造方法,所以new一次就会调用构造方法一次。如果继承体系中既有构造方法,又有静态代码块,那么首先执行最顶层的类的静态代码块,一直执行到最底层类的静态代码块,然后再去执行最顶层类的构造方法,一直执行到最底层类的构造方法。注意:静态代码块只会执行一次。
4、static修饰类:这个有点特殊,首先,static是可以用来修饰类的,但是static是不允许用来修饰普通类,只能用来修饰内部类,被static所修饰的内部类可以用new关键字来直接创建一个实例,不需要先创建外部类实例。static内部类可以被其他类实例化和引用(即使它是顶级类)。
其实理解起来也简单。因为static主要是修饰类里面的成员,包括内部类、属性、方法这些。修饰这些变量的目的也很单纯,那就是暗示这个成员在该类之中是唯一的一份拷贝,即便是不断的实例化该类,所有的这个类的对象都会共享这些static成员。这样就好办了。因为是共享的、唯一的,所以,也就不需要在实例化这个类以后再通过这个类来调用这个成员了,显然有点麻烦,所以就简单一点,直接通过类名直接调用static成员,更加直接。然而这样设置之后,就出现了一个限制,就是,static方法之中不能访问非static属性,因为这个时候非static属性可能还没有给他分配内存,该类还没有实例化。
所以,通常,static 关键字意味着应用它的实体在声明该实体的类的任何特定实例外部可用。
可以从类的外部调用 static 方法,而不用首先实例化该类。这样的引用始终包括类名作为方法调用的限定符。
- strictfp 严格,精准
strictfp的意思是FP-strict,也就是说精确浮点的意思。在Java虚拟机进行浮点运算时,如果没有指定strictfp关键字时,Java的编译器以及运行环境在对浮点运算的表达式是采取一种近似于我行我素的行为来完成这些操作,以致于得到的结果往往无法令人满意。而一旦使用了strictfp来声明一个类、接口或者方法时,那么所声明的范围内Java的编译器以及运行环境会完全依照浮点规范IEEE-754来执行。因此如果想让浮点运算更加精确,而且不会因为不同的硬件平台所执行的结果不一致的话,那就请用关键字strictfp。
可以将一个类、接口以及方法声明为strictfp,但是不允许对接口中的方法以及构造函数声明strictfp关键字。
- synchronized线程、同步
synchronized 关键字可以应用于方法或语句块,并为一次只应由一个线程执行的关键代码段提供保护。
synchronized 关键字可防止代码的关键代码段一次被多个线程执行。
如果应用于静态方法,那么,当该方法一次由一个线程执行时,整个类将被锁定。
如果应用于实例方法,那么,当该方法一次由一个线程访问时,该实例将被锁定。
如果应用于对象或数组,当关联的代码块一次由一个线程执行时,对象或数组将被锁定。
一般的用法有:
1、synchronized 方法控制对类成员变量的访问:每个类实例对应一把锁,
每个synchronized 方法都必须获得调用该方法的类实例的锁方能执行,否则所属线程阻塞,方法一旦执行,就独占该锁,直到从该方法返回时才将锁释放,此后被阻塞的线程方能获得该锁,重新进入可执行状态。这种机制确保了同一时刻对于每一个类实例,其所有声明为 synchronized 的成员函数中至多只有一个处于可执行状态(因为至多只有一个能够获得该类实例对应的锁),从而有效避免了类成员变量的访问冲突(只要所有可能访问类成员变量的方法均被声明为 synchronized)。
在Java中,不光是类实例,每一个类也对应一把锁,这样我们也可将类的静态成员函数声明为 synchronized ,以控制其对类的静态成员变量的访问。
synchronized 方法的缺陷:若将一个大的方法声明为synchronized 将会大大影响效率,典型地,若将线程类的方法 run() 声明为synchronized ,由于在线程的整个生命期内它一直在运行,因此将导致它对本类任何synchronized 方法的调用都永远不会成功。当然我们可以通过将访问类成员变量的代码放到专门的方法中,将其声明为 synchronized ,并在主方法中调用来解决这一问题,但是 Java 为我们提供了更好的解决办法,那就是 synchronized块。
2、synchronized块。
当两个并发线程访问同一个对象object中的这个synchronized(this)同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。
然而,当一个线程访问object的一个synchronized(this)同步代码块时,另一个线程仍然可以访问该object中的非synchronized(this)同步代码块。
尤其关键的是,当一个线程访问object的一个synchronized(this)同步代码块时,其他线程对object中所有其它synchronized(this)同步代码块的访问将被阻塞。同样适用其它同步代码块。也就是说,当一个线程访问object的一个synchronized(this)同步代码块时,它就获得了这个object的对象锁。结果,其它线程对该object对象所有同步代码部分的访问都被暂时阻塞。
这里的关键之处在于,这个object的对象锁只有一把,一把锁对应一个线程。
- transient 短暂
transient 关键字可以应用于类的成员变量,以便指出该成员变量不应在包含它的类实例已序列化时被序列化。
当一个对象被串行化的时候,transient型变量的值不包括在串行化的表示中,然而非transient型的变量是被包括进去的。
Java的serialization提供了一种持久化对象实例的机制。当持久化对象时,可能有一个特殊的对象数据成员,我们不想用serialization机制来保存它。为了在一个特定对象的一个域上关闭serialization,可以在这个域前加上关键字transient。
transient是Java语言的关键字,用来表示一个域不是该对象串行化的一部分。当一个对象被串行化的时候,transient型变量的值不包括在串行化的表示中,然而非transient型的变量是被包括进去的。
- volatile 易失
volatile 关键字用于表示可以被多个线程异步修改的成员变量。
注意:volatile 关键字在许多 Java 虚拟机中都没有实现。 volatile 的目标用途是为了确保所有线程所看到的指定变量的值都是相同的。
Volatile修饰的成员变量在每次被线程访问时,都强迫从主内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到主内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
Java语言规范中指出:
为了获得最佳速度,允许线程保存共享成员变量的私有拷贝,而且只当线程进入或者离开同步代码块时才与共享成员变量的原始值对比。
这样当多个线程同时与某个对象交互时,就必须要注意到要让线程及时的得到共享成员变量的变化。
而volatile关键字就是提示VM:对于这个成员变量不能保存它的私有拷贝,而应直接与共享成员变量交互。
使用建议:在两个或者更多的线程访问的成员变量上使用volatile。当要访问的变量已在synchronized代码块中,或者为常量时,不必使用。
由于使用volatile屏蔽掉了VM中必要的代码优化,所以在效率上比较低,因此一定在必要时才使用此关键字。
Java 语言中的 volatile 变量可以被看作是一种 “程度较轻的 synchronized”;与 synchronized 块相比,volatile 变量所需的编码较少,并且运行时开销也较少,但是它所能实现的功能也仅是 synchronized 的一部分。
3、程序控制语句
- break 跳出,中断
break 关键字用于提前退出 for、while 或 do 循环,或者在 switch 语句中用来结束 case 块。
break 总是退出最深层的 while、for、do 或 switch 语句。
- continue 继续
continue 关键字用来跳转到 for、while 或 do 循环的下一个迭代。
continue 总是跳到最深层 while、for 或 do 语句的下一个迭代。
- return 返回
return 关键字会导致方法返回到调用它的方法,从而传递与返回方法的返回类型匹配的值。
如果方法具有非 void 的返回类型,return 语句必须具有相同或兼容类型的参数。
返回值两侧的括号是可选的。
- do 运行
do 关键字用于指定一个在每次迭代结束时检查其条件的循环。
do 循环体至少执行一次。
条件表达式后面必须有分号。
- while 循环
while 关键字用于指定一个只要条件为真就会重复的循环。
- if 如果
if 关键字指示有条件地执行代码块。条件的计算结果必须是布尔值。
if 语句可以有可选的 else 子句,该子句包含条件为 false 时将执行的代码。
包含 boolean 操作数的表达式只能包含 boolean 操作数。
- else 否则
else 关键字总是在 if-else 语句中与 if 关键字结合使用。else 子句是可选的,如果 if 条件为 false,则执行该子句。
- for 循环
for 关键字用于指定一个在每次迭代结束前检查其条件的循环。
for 语句的形式为 for(initialize; condition; increment) 控件流进入 for 语句时,将执行一次 initialize 语句。
每次执行循环体之前将计算 condition 的结果。如果 condition 为 true,则执行循环体。
每次执行循环体之后,在计算下一个迭代的 condition 之前,将执行 increment 语句。
- instanceof 实例
instanceof 关键字用来确定对象所属的类。
- switch 观察
switch 语句用于基于某个表达式选择执行多个代码块中的某一个。
switch 条件的计算结果必须等于 byte、char、short 或 int。
case 块没有隐式结束点。break 语句通常在每个 case 块末尾使用,用于退出 switch 语句。
如果没有 break 语句,执行流将进入所有后面的 case 和/或 default 块。
- case 返回观察里的结果
case 用来标记 switch 语句中的每个分支。
case 块没有隐式结束点。break 语句通常在每个 case 块末尾使用,用于退出 switch 语句。
如果没有 break 语句,执行流将进入所有后面的 case 和/或 default 块。
- default 默认
default 关键字用来标记 switch 语句中的默认分支。
default 块没有隐式结束点。break 语句通常在每个 case 或 default 块的末尾使用,以便在完成块时退出 switch 语句。
如果没有 default 语句,其参数与任何 case 块都不匹配的 switch 语句将不执行任何操作。
4、错误处理
- try 捕获异常
try 关键字用于包含可能引发异常的语句块。
每个 try 块都必须至少有一个 catch 或 finally 子句。
如果某个特定异常类未被任何 catch 子句处理,该异常将沿着调用栈递归地传播到下一个封闭 try 块。如果任何封闭 try 块都未捕获到异常,Java 解释器将退出,并显示错误消息和堆栈跟踪信息。
- catch 处理异常
catch 关键字用来在 try-catch 或 try-catch-finally 语句中定义异常处理块。
开始和结束标记 { 和 } 是 catch 子句语法的一部分,即使该子句只包含一个语句,也不能省略这两个标记。
每个 try 块都必须至少有一个 catch 或 finally 子句。
如果某个特定异常类未被任何 catch 子句处理,该异常将沿着调用栈递归地传播到下一个封闭 try 块。如果任何封闭 try 块都未捕获到异常,Java 解释器将退出,并显示错误消息和堆栈跟踪信息。
- throw 抛出一个异常对象
throw 关键字用于引发异常。
throw 语句将 java.lang.Throwable 作为参数。Throwable 在调用栈中向上传播,直到被适当的 catch 块捕获。
引发非 RuntimeException 异常的任何方法还必须在方法声明中使用 throws 修饰符来声明它引发的异常。
- throws 声明一个异常可能被抛出
throws 关键字可以应用于方法,以便指出方法引发了特定类型的异常。
throws 关键字将逗号分隔的 java.lang.Throwables 列表作为参数。
引发非 RuntimeException 异常的任何方法还必须在方法声明中使用 throws 修饰符来声明它引发的异常。
要在 try-catch 块中包含带 throws 子句的方法的调用,必须提供该方法的调用者。
- finally
在异常处理机制当中,它的作用就像是人吃饭一样,必须得做的,不论有异常还是没有异常都要执行的代码就可以放到finally块当中去。finally块,必须要配合try块一起使用,不能单独使用,也不能直接和catch块一起使用。
finally 关键字用来定义始终在 try-catch-finally 语句中执行的块。
finally 块通常包含清理代码,用在部分执行 try 块后恢复正常运行。
5、包相关
- import 引入
import 关键字使一个包中的一个或所有类在当前 Java 源文件中可见。可以不使用完全限定的类名来引用导入的类。
当多个包包含同名的类时,许多 Java 程序员只使用特定的 import 语句(没有“*”)来避免不确定性。
- package 包
package 关键字指定在 Java 源文件中声明的类所驻留的 Java 包。
package 语句(如果出现)必须是 Java 源文件中的第一个非注释性文本。
例:java.lang.Object。
如果 Java 源文件不包含 package 语句,在该文件中定义的类将位于“默认包”中。请注意,不能从非默认包中的类引用默认包中的类。
6、基本类型
- boolean 布尔型
boolean 是 Java 原始类型。boolean 变量的值可以是 true 或 false。
boolean 变量只能以 true 或 false 作为值。boolean 不能与数字类型相互转换。
包含 boolean 操作数的表达式只能包含 boolean 操作数。
Boolean 类是 boolean 原始类型的包装对象类。
- byte 字节型
byte 是 Java 原始类型。byte 可存储在 [-128, 127] 范围以内的整数值。
Byte 类是 byte 原始类型的包装对象类。它定义代表此类型的值的范围的 MIN_VALUE 和 MAX_VALUE 常量。
Java 中的所有整数值都是 32 位的 int 值,除非值后面有 l 或 L(如 235L),这表示该值应解释为 long。
- char 字符型
char 是 Java 原始类型。char 变量可以存储一个 Unicode 字符。
可以使用下列 char 常量:
\b - 空格, \f - 换页, \n - 换行, \r - 回车, \t - 水平制表符, ' - 单引号, " - 双引号, \ - 反斜杠, \xxx - 采用 xxx 编码的 Latin-1 字符。\x 和 \xx 均为合法形式,但可能引起混淆。 \uxxxx - 采用十六进制编码 xxxx 的 Unicode 字符。
Character 类包含一些可用来处理 char 变量的 static 方法,这些方法包括 isDigit()、isLetter()、isWhitespace() 和 toUpperCase()。
char 值没有符号。
- double 双精度
double 是 Java 原始类型。double 变量可以存储双精度浮点值。
由于浮点数据类型是实际数值的近似值,因此,一般不要对浮点数值进行是否相等的比较。
Java 浮点数值可代表无穷大和 NaN(非数值)。Double 包装对象类用来定义常量 MIN_VALUE、MAX_VALUE、NEGATIVE_INFINITY、POSITIVE_INFINITY 和 NaN。
- float 浮点
float 是 Java 原始类型。float 变量可以存储单精度浮点值。
使用此关键字时应遵循下列规则:
Java 中的浮点文字始终默认为双精度。要指定单精度文字值,应在数值后加上 f 或 F,如 0.01f。
由于浮点数据类型是实际数值的近似值,因此,一般不要对浮点数值进行是否相等的比较。
Java 浮点数值可代表无穷大和 NaN(非数值)。Float 包装对象类用来定义常量 MIN_VALUE、MAX_VALUE、NEGATIVE_INFINITY、POSITIVE_INFINITY 和 NaN。
- int 整型
int 是 Java 原始类型。int 变量可以存储 32 位的整数值。
Integer 类是 int 原始类型的包装对象类。它定义代表此类型的值的范围的 MIN_VALUE 和 MAX_VALUE 常量。
Java 中的所有整数值都是 32 位的 int 值,除非值后面有 l 或 L(如 235L),这表示该值应解释为 long。
- long 长整型
long 是 Java 原始类型。long 变量可以存储 64 位的带符号整数。
Long 类是 long 原始类型的包装对象类。它定义代表此类型的值的范围的 MIN_VALUE 和 MAX_VALUE 常量。
Java 中的所有整数值都是 32 位的 int 值,除非值后面有 l 或 L(如 235L),这表示该值应解释为 long。
- short 短整型
short 是 Java 原始类型。short 变量可以存储 16 位带符号的整数。
Short 类是 short 原始类型的包装对象类。它定义代表此类型的值的范围的 MIN_VALUE 和 MAX_VALUE 常量。
Java 中的所有整数值都是 32 位的 int 值,除非值后面有 l 或 L(如 235L),这表示该值应解释为 long。
- null 空
null 是 Java 的保留字,表示无值。
将 null 赋给非原始变量相当于释放该变量先前所引用的对象。
不能将 null 赋给原始类型(byte、short、int、long、char、float、double、boolean)变量。
- true 真
true 关键字表示 boolean 变量的两个合法值中的一个。
- false 假
false 关键字代表 boolean 变量的两个合法值之一。
7、变量引用
- super 父类,超类
super 关键字用于引用使用该关键字的类的超类。
作为独立语句出现的 super 表示调用超类的构造方法。
super.() 表示调用超类的方法。只有在如下情况中才需要采用这种用法:要调用在该类中被重写的方法,以便指定应当调用在超类中的该方法。
- this 本类
this 关键字用于引用当前实例。
当引用可能不明确时,可以使用 this 关键字来引用当前的实例。
- void 无返回值
void 关键字表示 null 类型。
void 可以用作方法的返回类型,以指示该方法不返回值。
8、保留字
正确识别java语言的关键字(keyword)和保留字(reserved word)是十分重要的。Java的关键字对java的编译器有特殊的意义,他们用来表示一种数据类型,或者表示程序的结构等。保留字是为java预留的关键字,他们虽然现在没有作为关键字,但在以后的升级版本中有可能作为关键字。
识别java语言的关键字,不要和其他语言如c/c++的关键字混淆。
const和goto是java的保留字。 所有的关键字都是小写
- goto 跳转
goto 保留关键字,但无任何作用。结构化程序设计完全不需要 goto 语句即可完成各种流程,而 goto 语句的使用往往会使程序的可读性降低,所以 Java 不允许 goto 跳转。
- const 静态
const 保留字,是一个类型修饰符,使用const声明的对象不能更新。与final某些类似。