目录
1. 概述 学过Java的都知道,Java从一开始就打着平台无关性的旗号,说“一次编写,到处运行”,其实说到无关性,Java平台还有另外一个无关性那就是语言无关性。实现语言无关性,那么Java体系中的class文件结构或者说是字节码就显得相当重要了,其实Java从刚开始的时候就有两套规范,一个是Java语言规范,另外一个是Java虚拟机规范,Java语言规范只是规定了Java语言相关的约束以及规则,而虚拟机规范则才是真正从跨平台的角度去设计的。
Java代码要想执行,需要先被编译成Class文件,即使Java字节码文件,然后才能够在JVM上执行。
那么现在我们简单的了解下Java字节码究竟是什么。这种类汇编的指令有是如何在JVM上面执行的呢?
在Class文件中,Java方法里的方法体,也就是代表着一个Java源码程序中程序的部分存储在方法表集合的Code属性中。存储在Code属性中的是字节码,也就是编译后的程序。Java虚拟机的指令由两部分组成,首先是一个字节长度、代表某种含义的数字(即操作码),在操作码后面跟着零个或多个代表这个操作所需的参数(即操作数)。由于Java虚拟机采用的是面向操作数栈而不是寄存器的架构,所以大多数指令不包含操作数,只有一个操作码。
操作码的长度只有一个字节,这就限制了操作码的个数不超过256个。同时,Class文件格式放弃了编译后代码的操作数长度对齐,这就意味着虚拟机处理那些超过一个字节的数据时,不得不在运行时从字节中重建出具体数据的结构。比如,如果要将一个两个字节长的无符号整数使用两个无符号字节存储起来分别是byte1和byte2,那么就需要这样构造出原始的无符号整数:
(byte1<<8) | byte2
操作数的数量以及长度,取决于操作码,若一个操作数长度超过了一个字节,将会以Big-Endian顺序存储(高位在前字节码)。
这样会在某种程度上导致执行字节码时损失一些性能。但这样做也有好处,那就是由于不需要对齐,省去了中间的填充与间隔符号;用一个字节来表示操作码,也是为了获得短小的编译代码。这样就尽可能的减少了编译后的代码的长度,非常适合网络传输。
如果不考虑异常处理的话,那么Java虚拟机的解释器可以使用下面的伪代码作为基本的执行模型来理解:
1 2 3 4 5 6 7 8 do { 自动计算PC 寄存器的值加1 ; 根据PC 寄存器的指示位置,从字节码流中取出操作码; if (字节码存在操作数) 从字节码流中取出操作数; 执行操作码所定义的操作; }while (字节码长度>0 );
2. 举个栗子 可能大家现在有点不明觉厉哦,那么咱们先上代码,看看是个什么情况。
首先是一个简单的在控制台打印“Hello”的Java代码,如下:
1 2 3 4 5 6 7 public class SimpleClass { public void sayHello() { System.out.println("Hello" ); } }
然后我们使用javac SimpleClass.java命令,编译该Java代码,生成相应的Class文件。然后,继续在终端中使用javap -verbose SimpleClass,打印Class文件中的内容。如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 Classfile /C: /Users/yalechen/Desktop/JVM /Java Byte Code/samples/SimpleClass.class Last modified 2016 -8 -16 ; size 400 bytes MD5 checksum 92d47034320261dac69592f3c3e33c2e Compiled from "SimpleClass.java" public class SimpleClass minor version: 0 major version: 52 flags: ACC_PUBLIC , ACC_SUPER Constant pool: { public SimpleClass(); descriptor: ()V flags: ACC_PUBLIC Code: stack=1 , locals=1 , args_size=1 0 : aload_0 1 : invokespecial 4 : return LineNumberTable: line 3 : 0 public void sayHello(); descriptor: ()V flags: ACC_PUBLIC Code: stack=2 , locals=1 , args_size=1 0 : getstatic 3 : ldc 5 : invokevirtual 8 : return LineNumberTable: line 6 : 0 line 7 : 8 } SourceFile: "SimpleClass.java"
我们从上往下依次解析。
首先是该Class文件的整体信息介绍,包括文件所在路径、最近修改时间、文件大小、MD5校验值、从哪个Java编译而来。接下来才是正文。
我们一步一步来:
1) 该类的声明
2) Minor version,表示Class文件的次版本号。Major version,表示Class文件的主版本号。major_version和minor_version主要用来表示当前的虚拟机是否接受当前这种版本的Class文件。不同版本的Java编译器编译的Class文件对应的版本是不一样的。高版本的虚拟机支持低版本的编译器编译的 Class文件结构。比如Java SE 6.0对应的虚拟机支持Java SE 5.0的编译器编译的Class文件结构,反之则不行。
3) Flags,是该类的一些标识,包括访问权限(public、private、protected),父类、实现的接口等等。
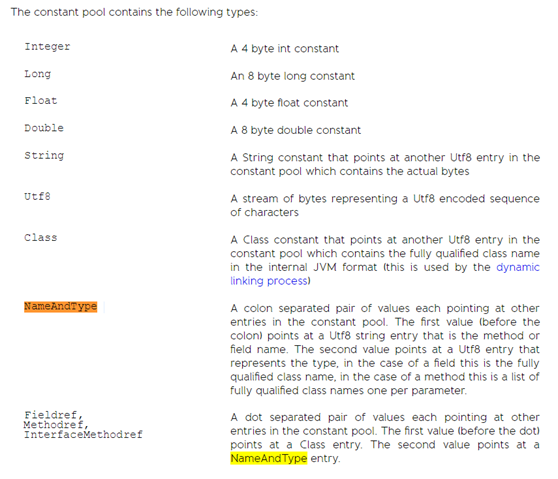
4) Constant pool,常量池。以下的一些都是定义的常量。这个算是Java代码编译上的一种优化,把一些引用明确的变量、方法、类等,转换成直接引用。
在能够唯一确定方法的直接引用的时候,虚拟机会将常量表里的符号引用转换为直接引用。但是如果方法是动态绑定的,也就是说在编译期我们并不知道使用哪个方法(或者叫不知道使用方法的哪个版本),那么这个时候就需要在运行时才能确定哪个版本的方法将被调用,这个时候才能将符号引用转换为直接引用。这个问题提到的多个版本的方法在java中的重载和多态重写问题息息相关。
具体的定义,比如:
#1 = Methodref #6.#14 // java/lang/Object."<init>":()V
#1是定义的引用的别称;
Methodref是该引用的具体类别,还有好几种不同的类别,之后会提及;
#6.#14是具体的引用名称,不过此时的引用名称也是有下面定义的引用别称来表示的。后面的双斜杠注释表示对引用的解释。
5) 花括号中的便是SimpleClasss类的内容了。其中是一个一个的方法定义。
6) public SimpleClass();这个是构造方法的声明。简直就是Java代码有没有。
7) descriptor: ()V描述。()V,看到括号里面没有参数,V便是Void,所以这是个无参无返回值的方法。
8) flags的含义跟跟上面提及的一样。
9) code属性,表示的是方法的具体内容。
10)stack、locals以及args_size,读入栈深度建立符合要求的操作数栈,读入局部变量大小建立符合要求的局部变量表,根据参数个数向局部变量表中依序加入参数(第一个参数是引用当前对象的this,所以空参数列表的参数数也是1)
11)LineNumberTable,是指每一个java字节码指令对应java代码文件中的第几行,以方便定位。
12)同理,sayHello方法也是如此道理。
13)SourceFile,这是源代码。
不知大家看懂了多少,先凑合着来,慢慢理清头绪。
3. Class文件结构 首先需要明确如下几点:
1)Class文件是由8个字节为基础的字节流构成的,这些字节流之间都严格按照规定的顺序排列,并且字节之间不存在任何空隙,对于超过8个字节的数据,将按照Big-Endian的顺序存储的,也就是说高位字节存储在低的地址上面,而低位字节存储到高地址上面,其实这也是class文件要跨平台的关键,因为 PowerPC架构的处理采用Big-Endian的存储顺序,而x86系列的处理器则采用Little-Endian的存储顺序,因此为了Class文件在各中处理器架构下保持统一的存储顺序,虚拟机规范必须对起进行统一。
2) Class文件结构采用类似C语言的结构体来存储数据的,主要有两类数据项,无符号数和表,无符号数用来表述数字,索引引用以及字符串等,比如u1,u2,u4,u8分别代表1个字节,2个字节,4个字节,8个字节的无符号数,而表是有多个无符号数以及其它的表组成的复合结构。
明确了上面的两点以后,我们接下来后来看看Class文件中按照严格的顺序排列的字节流都具体包含些什么数据:
在看上图的时候,有一点我们需要注意,比如cp_info,cp_info表示常量池,上图中用 constant_pool[constant_pool_count-1]的方式来表示常量池有constant_pool_count-1个常量,它这里是采用数组的表现形式,但是大家不要误以为所有的常量池的常量长度都是一样的,其实这个地方只是为了方便描述采用了数组的方式,但是这里并不像编程语言那里,一个int型的数组,每个int长度都一样。明确了这一点以后,我们在回过头来看看上图中每一项都具体代表了什么含义。
1)u4 magic 表示魔数,并且魔数占用了4个字节,魔数到底是做什么的呢?它其实就是表示一下这个文件的类型是一个Class文件,而不是一张JPG图片,或者AVI的电影。而Class文件对应的魔数是0xCAFEBABE.
2)u2 minor_version 表示Class文件的次版本号,并且此版本号是u2类型的无符号数表示。
3)u2 major_version 表示Class文件的主版本号,并且主版本号是u2类型的无符号数表示。major_version和minor_version主要用来表示当前的虚拟机是否接受当前这种版本的Class文件。不同版本的Java编译器编译的Class文件对应的版本是不一样的。高版本的虚拟机支持低版本的编译器编译的 Class文件结构。比如Java SE 6.0对应的虚拟机支持Java SE 5.0的编译器编译的Class文件结构,反之则不行。
4)u2 constant_pool_count 表示常量池的数量。这里我们需要重点来说一下常量池是什么东西,请大家不要与Jvm内存模型中的运行时常量池混淆了,Class文件中常量池主要存储了字面量以及符号引用,其中字面量主要包括字符串,final常量的值或者某个属性的初始值等等,而符号引用主要存储类和接口的全限定名称,字段的名称以及描述符,方法的名称以及描述符,这里名称可能大家都容易理解,至于描述符的概念,放到下面说字段表以及方法表的时候再说。另外大家都知道Jvm的内存模型中有堆,栈,方法区,程序计数器构成,而方法区中又存在一块区域叫运行时常量池,运行时常量池中存放的东西其实也就是编译器长生的各种字面量以及符号引用,只不过运行时常量池具有动态性,它可以在运行的时候向其中增加其它的常量进去,最具代表性的就是String的intern方法。
5)cp_info 表示常量池,这里面就存在了上面说的各种各样的字面量和符号引用。放到常量池的中数据项在The Java Virtual Machine Specification Java SE 7 Edition 中一共有14个常量,每一种常量都是一个表,并且每种常量都用一个公共的部分tag来表示是哪种类型的常量。
下面分别简单描述一下具体细节等到后面的实例中我们再细化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 CONSTANT_Utf8_info tag标志位为1 , UTF -8 编码的字符串 CONSTANT_Integer_info tag标志位为3 ,整形字面量 CONSTANT_Float_info tag标志位为4 ,浮点型字面量 CONSTANT_Long_info tag标志位为5 ,长整形字面量 CONSTANT_Double_info tag标志位为6 ,双精度字面量 CONSTANT_Class_info tag标志位为7 ,类或接口的符号引用 CONSTANT_String_info tag标志位为8 ,字符串类型的字面量 CONSTANT_Fieldref_info tag标志位为9 , 字段的符号引用 CONSTANT_Methodref_info tag标志位为10 ,类中方法的符号引用 CONSTANT_InterfaceMethodref_info tag标志位为11 , 接口中方法的符号引用 CONSTANT_NameAndType_info tag 标志位为12 ,字段和方法的名称以及类型的符号引用
可参考下图。
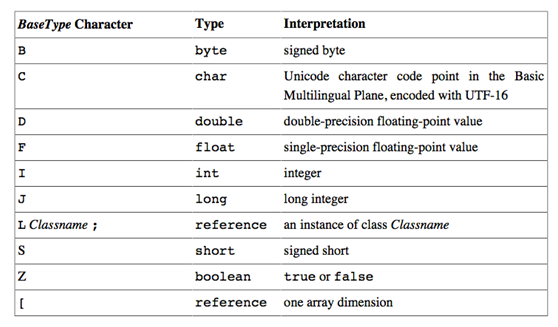
而这是在Java字节码中常出现的各种常量类型的字符描述符:
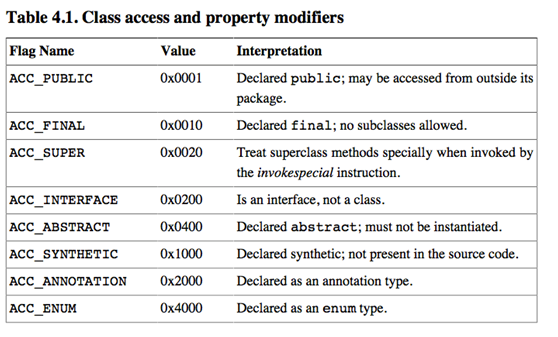
6)u2 access_flags 表示类或者接口的访问信息,具体如下图所示:
7)u2 this_class 表示类的常量池索引,指向常量池中CONSTANT_Class_info的常量
8)u2 super_class 表示超类的索引,指向常量池中CONSTANT_Class_info的常量
9)u2 interface_counts 表示接口的数量
10)u2 interface[interface_counts]表示接口表,它里面每一项都指向常量池中CONSTANT_Class_info常量
11)u2 fields_count 表示类的实例变量和类变量的数量
12)field_info fields[fields_count]表示字段表的信息,其中字段表的结构如下图所示:
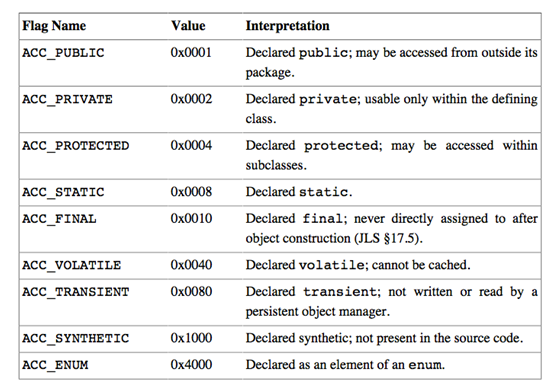
上图中access_flags表示字段的访问表示,比如字段是public,private,protect 等,name_index表示字段名称,指向常量池中类型是CONSTANT_UTF8_info的常量,descriptor_index表示字段的描述符,它也指向常量池中类型为 CONSTANT_UTF8_info的常量,attributes_count表示字段表中的属性表的数量,而属性表是则是一种用与描述字段,方法以及类的属性的可扩展的结构,不同版本的Java虚拟机所支持的属性表的数量是不同的。
13)u2 methods_count表示方法表的数量
14)method_info 表示方法表,方法表的具体结构如下图所示:
其中access_flags表示方法的访问表示,name_index表示名称的索引,descriptor_index表示方法的描述符,attributes_count以及attribute_info类似字段表中的属性表,只不过字段表和方法表中属性表中的属性是不同的,比如方法表中就Code属性,表示方法的代码,而字段表中就没有Code属性。Code属性的结构如下图:
attribute_name_index指向常量池中值为Code的常量;
attribute_length表示Code属性表的长度(这里需要注意的时候长度不包括attribute_name_index和attribute_length的6个字节的长度);
max_stack表示最大栈深度,虚拟机在运行时根据这个值来分配栈帧中操作数的深度,而max_locals代表了局部变量表的存储空间;
max_locals的单位为slot,slot是虚拟机为局部变量分配内存的最小单元,在运行时,对于不超过32位类型的数据类型,比如 byte,char,int等占用1个slot,而double和Long这种64位的数据类型则需要分配2个slot,另外max_locals的值并不是所有局部变量所需要的内存数量之和,因为slot是可以重用的,当局部变量超过了它的作用域以后,局部变量所占用的slot就会被重用;
code_length代表了字节码指令的数量,而code表示的时候字节码指令,从上图可以知道code的类型为u1,一个u1类型的取值为0x00-0xFF,对应的十进制为0-255,目前虚拟机规范已经定义了200多条指令;
exception_table_length以及exception_table分别代表方法对应的异常信息;
attributes_count和attribute_info分别表示了Code属性中的属性数量和属性表,从这里可以看出Class的文件结构中,属性表是很灵活的,它可以存在于Class文件,方法表,字段表以及Code属性中。
15) attribute_count表示属性表的数量,说到属性表,我们需要明确以下几点:
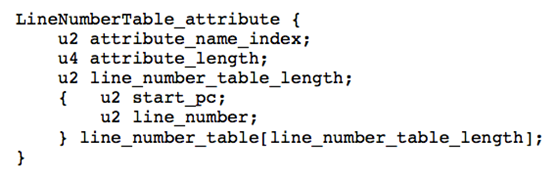
16)LineNumberTable,用于描述java源代码的行号和字节码行号的对应关系,它不是运行时必需的属性,如果通过-g:none的编译器参数来取消生成这项信息的话,最大的影响就是异常发生的时候,堆栈中不能显示出出错的行号,调试的时候也不能按照源代码来设置断点,接下来我们再看一下LineNumberTable的结构如下图所示:
其中attribute_name_index表示常量池的索引,attribute_length表示属性长度,而start_pc和 line_number分表表示字节码的行号和源代码的行号。
17)SourceFile,SourceFile的结构如下图所示:
其中attribute_length为属性的长度,sourcefile_index指向常量池中值为源代码文件名称的常量。
4. 指令 以下是具体使用到的Java字节码指令集。
1) 字节码与数据类型 在Java虚拟机的指令集中,大多数的指令都包含了操作所对应的数据类型信息。比如iload指令表示从局部变量表中加载int型数据到操作数栈中,而fload表示加载float类型的数据。不过,这两条指令再虚拟机的内部可能是由同一段代码来实现的,但在class文件中必须有自己的操作码。
我们已经知道Java指令的长度只有一个字节,这就限制了指令集的大小。如果每个指令都像上面两个指令那样包含所有的数据类型,那么就有可能导致指令过多。因此,Java虚拟机的指令集对于特定的操作只提供了有限的类型相关指令去支持它。比如,大多数指令没有支持整数类型byte、char和short,甚至没有指令支持boolean类型。
这些指令中都有特殊的字符来表示专门支持的类型:i代表int类型,l代表long,s代表short,b代表byte,c代表char,f代表float,d代表double,a代表Reference。
这里仅仅介绍一下指令的种类以及作用,并不会过多的介绍各个指令的含义以及使用,需要的话可以查看《Java虚拟机规范(Java SE 7版)》。
2) 加载和存储指令 加载指令用于将局部变量表中的数据传送到操作数栈中,而存储指令用于将操作数栈中的结果传送到局部变量表中。这类指令包括如下几种:
将一个局部变量加载到操作栈,比如iload、iload、fload、fload、lload、lload、dload、dload、aload、aload;
将一个数值从操作数栈存储到局部变量表,比如istore、istore、lstore、lstore、fstore、fstore、dstore、dstore、astore、astore;
将一个常量加载到操作数栈,比如bipush、sipush、ldc、ldc_w、ldc2_w、aconst_null、iconst_ml、iconst_、lconst_、fconst_、dconst_;
扩充局部变量表的访问索引的指令:wide;
上面中带尖括号的指令实际是一组指令。比如iload,代表了iload_1、iload_2和iload_3。这几组指令是某个带操作数的指令(比如iload)的特殊形式,它们省略了操作数,不过操作数隐含在指令中。
3) 运算指令 运算或算术指令用于对一个或两个操作数栈上的值进行某种特定的运算,并将结果存入栈顶。大体上可以分为两种,对整数进行运算的指令和对浮点数进行运算的指令。不过,由于没有支持byte、short、char和boolean的算术指令,对于这些数据的运算,会把它们转化为int类型进行运算。指令列出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 加法指令:iadd、ladd、fadd、dadd; 减法指令:isub、lsub、fsub、dsub; 乘法指令:imul、lmul、fmul、dmul; 除法指令:idiv、ldiv、fdiv、ddiv; 求余指令:irem、lrem、frem、drem; 取反指令:ineg、lneg、fneg、dneg; 位移指令:ishl、ishr、iushr、lshl、lshr、lushr; 按位或指令:ior、lor; 按位与指令:iand、land; 按位异或指令:ixor、lxor; 局部变量自增指令:iinc; 比较指令:dcmpg、dcmpl、fcmpg、fcmpl、lcmp;
4) 类型转换指令 类型转换指令用来将两种不同类型进行转换,这些转换操作一般用于实现代码中的显示类型转换操作,或者前面提到的字节码指令集中数据类型相关指令无法与数据类型一一对应的问题。
虚拟机直接支持宽化类型转换,即小范围类型向大范围类型的安全转换,不需要显示的转换指令。
但是处理窄化类型转换时,必须显示使用转换指令来完成,这些指令包括:i2b、i2c、i2s、l2i、f2l、d2i、d2l和d2f。这些指令可能会导致数值的精度丢失。
5) 对象创建与访问指令 虽然类实例和数组都是对象,但是虚拟机创建类对象和数组的指令是不同的。对象创建后,就可以通过对象访问指令获取对象实例或者数组实例中的字段或数组元素,指令如下:
创建类实例的指令:new;
创建数组的指令:newarray、anewarray、multianewarray;
访问类字段和实例字段的指令:getfield、putfield、getstatic、putstatic;
把一个数组元素加载到操作数栈的指令:baload、caload、saload、iaload、laload、faload、daload、aaload;
将一个操作数栈的值存储到数组元素中的指令:bastore、castore、sastore、iastore、fastore、dastore、aastore;
取数组长度的指令:arraylength;
检查类实例类型的指令:instanceof、checkcast;
6) 操作数栈管理指令 就像操作一个普通的栈一样,Java虚拟机提供了一些用于直接操作操作数栈的指令,包括:
将操作数栈的栈顶一个或两个元素出栈:pop、pop2;
复制栈顶一个或两个数值并将复制值或双份的复制值重新压入栈顶:dup、dup2、dup_x1、dup2_x1、dup_x2、dup2_x2;
将栈顶最顶端的两个数值互换:swap;
7) 控制转移指令 控制转移指令可以让Java虚拟机有条件或无条件的从指定的位置指令而不是控制转移指令的下一条指令继续执行,可以理解为控制转移指令改变了PC寄存器的值。指令如下:
条件分支:ifeq、iflt、ifle、ifgt、ifge、ifnonnull、if_icmpeq、if_icmpne、if_icmplt、if_icmpgt、、if_icmpge、if_acmpeq和if_acmpne;
复合条件分支:tableswitch、lookupswitch;
无条件分支:goto、goto_w、jsr、jsr_w、ret;
8) 方法调用和返回指令 这里仅仅列出5条用于方法调用的指令:
invokevirtual指令用于调用对象的实例方法,根据对象的实际类型进行分派(虚方法分派),这也是Java语言中最常见的方法分派方式;
invokeinterface指令用于调用接口方法,它会在运行时搜索一个实现了这个接口方法的对象,找出适合的方法进行调用;
invokespecial指令用于调用一些需要特殊处理的实例方法,包括实例初始化方法、私有方法和父类方法;
invokestatic指令用于调用类方法(static方法);
invokedynamic指令用于在运行时动态解析出调用点限定符索引用的方法,并执行方法,前面4条指令的分派逻辑都固化在Java虚拟机内部,而invokedynamic指令的分派逻辑是由用户所设定的引导方法决定的;
方法调用指令与类型无关,但是方法返回指令是根据返回值的类型区分的,包括ireturn、lreturn、freturn、dreturn和areturn,另外还有一个return指令供声明为void的方法、实例初始化方法以及类和接口的类初始化方法使用。
9) 异常处理指令 在Java程序中显式抛出异常的操作(throw语句)都是由athrow指令来实现的,除了用throw语句显式抛出异常外,Java虚拟机规范还规定了许多运行时异常会在其他Java虚拟机指令检测到异常状况时自动抛出。
而在Java虚拟机中,处理异常(catch语句)不是由字节码指令来完成的,而是采用异常表来完成的。
10) 同步指令 Java虚拟机可以支持方法级的同步和方法内部一段指令序列的同步,这两种同步结构都是使用管程(Monitor)来支持的。
方法级的同步是隐式的,即不需要通过字节码指令来控制,它实现在方法调用和返回操作中。虚拟机可以从方法常量池的方法表结构中的ACC_SYNCHRONIZED访问标志得知一个方法是否声明为同步方法。当方法调用时,调用指令就会去检查方法的ACC_SYNCHRONIZED访问标志是否被设置了,如果设置,执行线程就要求持有管程。在方法执行期间,执行线程持有了管程,其他任何线程都无法再获取到同一个管程。如果一个方法在执行期间发生了异常,并在方法中无法处理此异常,那么这个同步方法所持有的管程将在异常抛出后自动释放。
同步一段指令集序列通常是由Java语言中的synchronized语句块表示的,Java虚拟机的指令集中有monitorenter和monitorexit指令来支持synchronized关键字的语义。正确实现synchronized关键字需要Javac编译器和Java虚拟机两者共同协作。编译器必须保证每个monitorenter指令都有对应的monitorexit指令。
5. 再看几个栗子 例1 Java源代码如下:
1 2 3 4 5 6 7 8 9 10 11 public class TestDemo { public static int minus(int x){ return -x; } public static void main(String[] args) { int x = 5 ; int y = minus(x); } }
Javap–verbose TestDemo之后,得到Java字节码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 Classfile /C: /Users/yalechen/Desktop/JVM /Java Byte Code/samples/TestDemo/TestDemo.class Last modified 2016 -8 -16 ; size 342 bytes MD5 checksum 77ff8854473da6d63caf8a5347bb3434 Compiled from "TestDemo.java" public class TestDemo minor version: 0 major version: 52 flags: ACC_PUBLIC , ACC_SUPER Constant pool: { public TestDemo(); descriptor: ()V flags: ACC_PUBLIC Code: stack=1 , locals=1 , args_size=1 0 : aload_0 1 : invokespecial 4 : return LineNumberTable: line 3 : 0 public static int minus(int); descriptor: (I)I //描述符描述的参数列表和返回类型.I表示int flags: ACC_PUBLIC, ACC_STATIC / /访问权限 Code: stack=1, locals=1, args_size=1 0: iload_0 / /将slot0压入栈顶,也就是传入的参数 1: ineg / /将栈顶的值弹出取负后压回栈顶 2: ireturn LineNumberTable: line 5: 0 public static void main(java.lang.String[]); descriptor: ([Ljava/lang /String;)V flags: ACC_PUBLIC, ACC_STATIC Code: / /确定可以访问后进入Code属性表执行命令 stack=1, locals=3, args_size=1 / /读入栈深度建立符合要求的操作数栈,读入局部变量大小建立符合要求的局部变量表,根据参数个数向局部变量表中依序加入参数(第一个参数是引用当前对象的this,所以空参数列表的参数数也是1) 0: iconst_5 / /前面 0 表示标识。将整数5压入栈顶 1: istore_1 / /将栈顶整数值存入局部变量表的slot1(slot0是参数this)到这为止,int x = 5; 2: iload_1 / /将slot1压入栈顶 3: invokestatic #2 / / Method minus:(I)I 调用静态累方法minus。二进制invokestatic方法用于调用静态方法,参数是根据常量池中已经转换为直接引用的常量,意即minus函数在方法区中的地址,找到这个地址调用函数,向其中加入的参数是栈顶的值 6: istore_2 / /此时的栈顶元素是经过了 minus 方法处理过了的 7: return LineNumberTable: line 8: 0 line 9: 2 line 10: 7 } SourceFile: "TestDemo.java"
例2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 //测试重载机制 public class TestDemo1 { static class Human{ } static class Man extends Human{ } static class Woman extends Human{ } public void sayHello(Human human) { System.out.println("hello human"); } public void sayHello(Man man) { System.out.println("hello man"); } public void sayHello(Woman woman) { System.out.println("hello woman"); } public static void main(String[] args) { TestDemo1 demo = new TestDemo1(); Human man = new Man(); Human woman = new Woman(); demo.sayHello(man); demo.sayHello(woman); } }
Java字节码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 Classfile /C: /Users/yalechen/Desktop/JVM /Java Byte Code/samples/TestDemo/TestDemo1.class Last modified 2016 -8 -16 ; size 883 bytes MD5 checksum 5a1df45f23bd666f3c6c716e50265345 Compiled from "TestDemo1.java" public class TestDemo1 //重载 minor version: 0 major version: 52 flags: ACC_PUBLIC, ACC_SUPER Constant pool: #1 = Methodref #14.#32 / / java/lang /Object."<init>":()V #2 = Fieldref #33.#34 / / java/lang /System.out:Ljava/io /PrintStream; #3 = String #35 / / hello human #4 = Methodref #36.#37 / / java/io /PrintStream.println:(Ljava/lang /String;)V #5 = String #38 / / hello man #6 = String #39 / / hello woman #7 = Class #40 / / TestDemo1 #8 = Methodref #7.#32 / / TestDemo1."<init>":()V #9 = Class #41 / / TestDemo1$Man #10 = Methodref #9.#32 / / TestDemo1$Man."<init>":()V #11 = Class #42 / / TestDemo1$Woman #12 = Methodref #11.#32 / / TestDemo1$Woman."<init>":()V #13 = Methodref #7.#43 / / TestDemo1.sayHello:(LTestDemo1$Human;)V #14 = Class #44 / / java/lang /Object #15 = Utf8 Woman #16 = Utf8 InnerClasses #17 = Utf8 Man #18 = Class #45 / / TestDemo1$Human #19 = Utf8 Human #20 = Utf8 <init> #21 = Utf8 ()V #22 = Utf8 Code #23 = Utf8 LineNumberTable #24 = Utf8 sayHello #25 = Utf8 (LTestDemo1$Human;)V #26 = Utf8 (LTestDemo1$Man;)V #27 = Utf8 (LTestDemo1$Woman;)V #28 = Utf8 main #29 = Utf8 ([Ljava/lang /String;)V #30 = Utf8 SourceFile #31 = Utf8 TestDemo1.java #32 = NameAndType #20:#21 / / "<init>":()V #33 = Class #46 / / java/lang /System #34 = NameAndType #47:#48 / / out:Ljava/io /PrintStream; #35 = Utf8 hello human #36 = Class #49 / / java/io /PrintStream #37 = NameAndType #50:#51 / / println:(Ljava/lang /String;)V #38 = Utf8 hello man #39 = Utf8 hello woman #40 = Utf8 TestDemo1 #41 = Utf8 TestDemo1$Man #42 = Utf8 TestDemo1$Woman #43 = NameAndType #24:#25 / / sayHello:(LTestDemo1$Human;)V #44 = Utf8 java/lang /Object #45 = Utf8 TestDemo1$Human #46 = Utf8 java/lang /System #47 = Utf8 out #48 = Utf8 Ljava/io /PrintStream; #49 = Utf8 java/io /PrintStream #50 = Utf8 println #51 = Utf8 (Ljava/lang /String;)V { public TestDemo1(); / /构造方法 descriptor: ()V flags: ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: invokespecial #1 / / Method java/lang /Object."<init>":()V 4: return LineNumberTable: line 1: 0 public void sayHello(TestDemo1$Human); descriptor: (LTestDemo1$Human;)V flags: ACC_PUBLIC Code: stack=2, locals=2, args_size=2 0: getstatic #2 / / Field java/lang /System.out:Ljava/io /PrintStream; 3: ldc #3 / / String hello human 5: invokevirtual #4 / / Method java/io /PrintStream.println:(Ljava/lang /String;)V 8: return LineNumberTable: line 11: 0 line 12: 8 public void sayHello(TestDemo1$Man); descriptor: (LTestDemo1$Man;)V flags: ACC_PUBLIC Code: stack=2, locals=2, args_size=2 0: getstatic #2 / / Field java/lang /System.out:Ljava/io /PrintStream; 3: ldc #5 / / String hello man 5: invokevirtual #4 / / Method java/io /PrintStream.println:(Ljava/lang /String;)V 8: return LineNumberTable: line 14: 0 line 15: 8 public void sayHello(TestDemo1$Woman); descriptor: (LTestDemo1$Woman;)V flags: ACC_PUBLIC Code: stack=2, locals=2, args_size=2 0: getstatic #2 / / Field java/lang /System.out:Ljava/io /PrintStream; 3: ldc #6 / / String hello woman 5: invokevirtual #4 / / Method java/io /PrintStream.println:(Ljava/lang /String;)V 8: return LineNumberTable: line 17: 0 line 18: 8 public static void main(java.lang.String[]); descriptor: ([Ljava/lang /String;)V flags: ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=4, args_size=1 0: new #7 / / class TestDemo1 3: dup 4: invokespecial #8 / / Method "<init>":()V 7: astore_1 8: new #9 / / class TestDemo1$Man 11: dup 12: invokespecial #10 / / Method TestDemo1$Man."<init>":()V 15: astore_2 16: new #11 / / class TestDemo1$Woman 19: dup 20: invokespecial #12 / / Method TestDemo1$Woman."<init>":()V 23: astore_3 24: aload_1 25: aload_2 26: invokevirtual #13 / / Method sayHello:(LTestDemo1$Human;)V 29: aload_1 30: aload_3 31: invokevirtual #13 / / Method sayHello:(LTestDemo1$Human;)V 34: return LineNumberTable: / /与源代码中的各行代码进行相互匹配 line 20: 0 line 21: 8 line 22: 16 line 23: 24 line 24: 29 line 25: 34 } SourceFile: "TestDemo1.java" InnerClasses: static #15= #11 of #7; / /Woman=class TestDemo1$Woman of class TestDemo1 static #17= #9 of #7; / /Man=class TestDemo1$Man of class TestDemo1 static #19= #18 of #7; / /Human=class TestDemo1$Human of class TestDemo1
例3 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 /*重写*/ public class TestDemo2 { static class Human{ public void sayHello() { System.out.println("hello human"); } } static class Man extends Human{ public void sayHello() { System.out.println("hello man"); } } static class Woman extends Human{ public void sayHello() { System.out.println("hello woman"); } } public static void main(String[] args) { Human man = new Man(); Human woman = new Woman(); man.sayHello(); woman.sayHello(); } }
Java字节码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 Classfile /C: /Users/yalechen/Desktop/JVM /Java Byte Code/samples/TestDemo/TestDemo2.class Last modified 2016 -8 -16 ; size 464 bytes MD5 checksum 2183e6c960f34e773da47dac5f8d717a Compiled from "TestDemo2.java" public class TestDemo2 minor version: 0 major version: 52 flags: ACC_PUBLIC , ACC_SUPER Constant pool: { public TestDemo2(); descriptor: ()V flags: ACC_PUBLIC Code: stack=1 , locals=1 , args_size=1 0 : aload_0 1 : invokespecial 4 : return LineNumberTable: line 3 : 0 public static void main(java.lang.String[]); descriptor: ([Ljava/lang/String;)V flags: ACC_PUBLIC , ACC_STATIC Code: stack=2 , locals=3 , args_size=1 0 : new 3 : dup 4 : invokespecial 7 : astore_1 8 : new 11 : dup 12 : invokespecial 15 : astore_2 16 : aload_1 17 : invokevirtual 20 : aload_2 21 : invokevirtual 24 : return LineNumberTable: line 21 : 0 line 22 : 8 line 23 : 16 line 24 : 20 line 25 : 24 } SourceFile: "TestDemo2.java" InnerClasses: static static static
可以从例2和例3看出,无论是重载还是重写,都是二进制指令invokevirtual调用了sayHello方法来执行的。
在重载中,程序调用的是参数实际类型不同的方法,但是虚拟机最终分派了相同外观类型(静态类型)的方法,这说明在重载的过程中虚拟机在运行的时候是只看参数的外观类型(静态类型)的,而这个外观类型(静态类型)是在编译的时候就已经确定的,和虚拟机没有关系。这种依赖静态类型来做方法的分配叫做静态分派。
在重写中,程序调用的是不同实际类型的同名方法,虚拟机依据对象的实际类型去寻找是否有这个方法,如果有就执行,如果没有去父类里找,最终在实际类型里找到了这个方法,所以最终是在运行期动态分派了方法。在编译的时候我们可以看到字节码指示的方法都是一样的符号引用,但是运行期虚拟机能够根据实际类型去确定出真正需要的直接引用。这种依赖实际类型来做方法的分配叫做动态分派。得益于java虚拟机的动态分派会在分派前确定对象的实际类型,面向对象的多态性才能体现出来。