Binaryen also provides a set of toolchain utilities that can
Parse and emit WebAssembly. In particular this lets you load WebAssembly, optimize it using Binaryen, and re-emit it, thus implementing a wasm-to-wasm optimizer in a single command.
Interpret WebAssembly as well as run the WebAssembly spec tests.
Integrate with Emscripten in order to provide a complete compiler toolchain from C and C++ to WebAssembly.
Polyfill WebAssembly by running it in the interpreter compiled to JavaScript, if the browser does not yet have native support (useful for testing).
As close as possible to WebAssembly so it is simple and fast to convert it to and from WebAssembly.
There are a few differences between Binaryen IR and the WebAssembly language:
Tree structure
Binaryen IR is a tree, i.e., it has hierarchical structure, for convenience of optimization. This differs from the WebAssembly binary format which is a stack machine.
Consequently Binaryen’s text format allows only s-expressions. WebAssembly’s official text format is primarily a linear instruction list (with s-expression extensions). Binaryen can’t read the linear style, but it can read a wasm text file if it contains only s-expressions.
Binaryen uses Stack IR to optimize “stacky” code (that can’t be represented in structured form).
When stacky code must be represented in Binaryen IR, such as with multivalue instructions and blocks, it is represented with tuple types that do not exist in the WebAssembly language. In addition to multivalue instructions, locals and globals can also have tuple types in Binaryen IR but not in WebAssembly. Experiments show that better support for multivalue could enable useful but small code size savings of 1-3%, so it has not been worth changing the core IR structure to support it better.
Block input values (currently only supported in catch blocks in the exception handling feature) are represented as pop subexpressions.
Binaryen 在读取 WebAssembly 二进制文件时会忽略无法访问的代码。这意味着如果您读取包含无法访问代码的 wasm 文件,该代码将被丢弃,就好像它已被优化一样(通常这就是您想要的,优化的程序无论如何都没有无法访问的代码,但是如果您编写一个未优化的文件并且然后阅读它,它可能看起来不同)。这种行为的原因是 WebAssembly 中无法访问的代码具有在 Binaryen IR 中难以处理的极端情况(它可能非常非结构化,并且如前所述,Binaryen IR 比 WebAssembly 更具结构化)。请注意,Binaryen 确实支持 .wat 文本文件中无法访问的代码,因为正如我们所见,Binaryen 仅支持结构化的 s 表达式。
Blocks
Binaryen IR 只有一个节点包含可变长度的操作数列表:块blocks。另一方面,WebAssembly 允许循环中的列表、if 臂和函数的顶层。Binaryen 的 IR 对所有非块节点都有一个操作数;这个操作数当然可以是一个块。这个属性的动机是许多通道需要特殊的代码来迭代列表,因此使用带有列表的单个 IR 节点可以简化它们。
As in wasm, blocks and loops may have names. Branch targets in the IR are resolved by name (as opposed to nesting depth). This has 2 consequences:
Blocks without names may not be branch targets.
Names are required to be unique. (Reading .wat files with duplicate names is supported; the names are modified when the IR is constructed).
As an optimization, a block that is the child of a loop (or if arm, or function toplevel) and which has no branches targeting it will not be emitted when generating wasm. Instead its list of operands will be directly used in the containing node. Such a block is sometimes called an “implicit block”.
Reference Types
The wasm text and binary formats require that a function whose address is taken by ref.func must be either in the table, or declared via an (elem declare func $..). Binaryen will emit that data when necessary, but it does not represent it in IR. That is, IR can be worked on without needing to think about declaring function references.
As a result, you might notice that round-trip conversions (wasm => Binaryen IR => wasm) change code a little in some corner cases.
When optimizing Binaryen uses an additional IR, Stack IR (see src/wasm-stack.h). Stack IR allows a bunch of optimizations that are tailored for the stack machine form of WebAssembly’s binary format (but Stack IR is less efficient for general optimizations than the main Binaryen IR). If you have a wasm file that has been particularly well-optimized, a simple round-trip conversion (just read and write, without optimization) may cause more noticeable differences, as Binaryen fits it into Binaryen IR’s more structured format. If you also optimize during the round-trip conversion then Stack IR opts will be run and the final wasm will be better optimized.
Notes when working with Binaryen IR:
如上所述,Binaryen IR 具有树结构。因此,每个表达式都应该只有一个父节点 - 您不应该通过让节点在树中多次出现来“重用”节点。这个限制的动机是当我们优化时我们修改节点,所以如果它们在树中出现多次,一个地方的变化可能会错误地出现在另一个地方
For similar reasons, nodes should not appear in more than one functions.
Intrinsics
Binaryen intrinsic functions look like calls to imports, e.g.,
1
(import "binaryen-intrinsics" "foo" (func $foo))
Implementing them that way allows them to be read and written by other tools, and it avoids confusing errors on a binary format error that could happen in those tools if we had a custom binary format extension.
An intrinsic method may be optimized away by the optimizer. If it is not, it must be lowered before shipping the wasm, as otherwise it will look like a call to an import that does not exist (and VMs will show an error on not having a proper value for that import). That final lowering is not done automatically. A user of intrinsics must run the pass for that explicitly, because the tools do not know when the user intends to finish optimizing, as the user may have a pipeline of multiple optimization steps, or may be doing local experimentation, or fuzzing/reducing, etc. Only the user knows when the final optimization happens before the wasm is “final” and ready to be shipped. Note that, in general, some additional optimizations may be possible after the final lowering, and so a useful pattern is to optimize once normally with intrinsics, then lower them away, then optimize after that, e.g.:
Each intrinsic defines its semantics, which includes what the optimizer is allowed to do with it and what the final lowering will turn it to. See intrinsics.h for the detailed definitions. A quick summary appears here:
call.without.effects: Similar to a call_ref in that it receives parameters, and a reference to a function to call, and calls that function with those parameters, except that the optimizer can assume the call has no side effects, and may be able to optimize it out (if it does not have a result that is used, generally).
MemoryPacking - Key “optimize data segments” pass that combines segments, removes unneeded parts, etc.
MergeBlocks - Merge a block to an outer one where possible, reducing their number.
MergeLocals - When two locals have the same value in part of their overlap, pick in a way to help CoalesceLocals do better later (split off from CoalesceLocals to keep the latter simple).
MinifyImportsAndExports - Minifies them to “a”, “b”, etc.
OptimizeAddedConstants - Optimize a load/store with an added constant into a constant offset.
OptimizeInstructions - Key peephole optimization pass with a constantly increasing list of patterns.
PickLoadSigns - Adjust whether a load is signed or unsigned in order to avoid sign/unsign operations later.
Precompute - Calculates constant expressions at compile time, using the built-in interpreter (which is guaranteed to be able to handle any constant expression).
ReReloop - Transforms wasm structured control flow to a CFG and then goes back to structured form using the Relooper algorithm, which may find more optimal shapes.
RedundantSetElimination - Removes a local.set of a value that is already present in a local. (Overlaps with CoalesceLocals; this achieves the specific operation just mentioned without all the other work CoalesceLocals does, and therefore is useful in other places in the optimization pipeline.)
RemoveUnsedBrs - Key “minor control flow optimizations” pass, including jump threading and various transforms that can get rid of a br or br_table (like turning a block with a br in the middle into an if when possible).
RemoveUnusedModuleElements - “Global DCE”, an LTO pass that removes imports, functions, globals, etc., when they are not used.
ReorderFunctions - Put more-called functions first, potentially allowing the LEB emitted to call them to be smaller (in a very large program).
ReorderLocals - Put more-used locals first, potentially allowing the LEB emitted to use them to be smaller (in a very large function). After the sorting, it also removes locals not used at all.
SimplifyGlobals - Optimizes globals in various ways, for example, coalescing them, removing mutability from a global never modified, applying a constant value from an immutable global, etc.
SimplifyLocals - Key “local.get/set/tee” optimization pass, doing things like replacing a set and a get with moving the set’s value to the get (and creating a tee) where possible. Also creates block/if/loop return values instead of using a local to pass the value.
Vacuum - Key “remove silly unneeded code” pass, doing things like removing an if arm that has no contents, a drop of a constant value with no side effects, a block with a single child, etc.
“LTO” in the above means an optimization is Link Time Optimization-like in that it works across multiple functions, but in a sense Binaryen is always “LTO” as it usually is run on the final linked wasm.
Binaryen uses git submodules (at time of writing just for gtest), so before you build you will have to initialize the submodules:
1 2
git submodule init git submodule update
After that you can build with CMake:
1
cmake . && make
A C++17 compiler is required. Note that you can also use ninja as your generator: cmake -G Ninja . && ninja.
To avoid the gtest dependency, you can pass -DBUILD_TESTS=OFF to cmake.
Binaryen.js can be built using Emscripten, which can be installed via the SDK).
1
emcmake cmake . && emmake make binaryen_js
Visual C++
Using the Microsoft Visual Studio Installer, install the “Visual C++ tools for CMake” component.
Generate the projects:
1 2 3
mkdir build cd build "%VISUAL_STUDIO_ROOT%\Common7\IDE\CommonExtensions\Microsoft\CMake\CMake\bin\cmake.exe" ..
Substitute VISUAL_STUDIO_ROOT with the path to your Visual Studio installation. In case you are using the Visual Studio Build Tools, the path will be “C:\Program Files (x86)\Microsoft Visual Studio\2017\BuildTools”.
From the Developer Command Prompt, build the desired projects:
1
msbuild binaryen.vcxproj
CMake generates a project named “ALL_BUILD.vcxproj” for conveniently building all the projects.
Running
wasm-opt
Run
1
bin/wasm-opt [.wasm or .wat file] [options] [passes, see --help] [--help]
wasm2js’s output is in ES6 module format - basically, it converts a wasm module into an ES6 module (to run on older browsers and Node.js versions you can use Babel etc. to convert it to ES5). Let’s look at a full example of calling that hello world wat; first, create the main JS file:
1 2 3
// main.mjs import { add } from"./hello_world.mjs"; console.log('the sum of 1 and 2 is:', add(1, 2));
The run this (note that you need a new enough Node.js with ES6 module support):
1 2 3
$ bin/wasm2js test/hello_world.wat -o hello_world.mjs $ node --experimental-modules main.mjs the sum of 1 and 2 is: 3
Things keep to in mind with wasm2js’s output:
You should run wasm2js with optimizations for release builds, using -O or another optimization level. That will optimize along the entire pipeline (wasm and JS). It won’t do everything a JS minifer would, though, like minify whitespace, so you should still run a normal JS minifer afterwards.
It is not possible to match WebAssembly semantics 100% precisely with fast JavaScript code. For example, every load and store may trap, and to make JavaScript do the same we’d need to add checks everywhere, which would be large and slow. Instead, wasm2js assumes loads and stores do not trap, that int/float conversions do not trap, and so forth. There may also be slight differences in corner cases of conversions, like non-trapping float to int.
wasm-ctor-eval
wasm-ctor-eval executes functions, or parts of them, at compile time. After doing so it serializes the runtime state into the wasm, which is like taking a “snapshot”. When the wasm is later loaded and run in a VM, it will continue execution from that point, without re-doing the work that was already executed.
(module ;; A global variable that begins at 0. (global $global (mut i32) (i32.const 0))
(import "import" "import" (func $import))
(func "main" ;; Set the global to 1. (global.set $global (i32.const 1))
;; Call the imported function. This *cannot* be executed at ;; compile time. (call $import)
;; We will never get to this point, since we stop at the ;; import. (global.set $global (i32.const 2)) ) )
We can evaluate part of it at compile time like this:
1
wasm-ctor-eval input.wat --ctors=main -S -o -
This tells it that there is a single function that we want to execute (“ctor” is short for “global constructor”, a name that comes from code that is executed before a program’s entry point) and then to print it as text to stdout. The result is this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
trying to eval main ...partial evalling successful, but stopping since could not eval: call import: import.import ...stopping (module (type $none_=>_none (func)) (import "import" "import" (func $import)) (global $global (mut i32) (i32.const 1)) (export "main" (func $0_0)) (func $0_0 (call $import) (global.set $global (i32.const 2) ) ) )
The logging shows us managing to eval part of main(), but not all of it, as expected: We can eval the first global.get, but then we stop at the call to the imported function (because we don’t know what that function will be when the wasm is actually run in a VM later). Note how in the output wasm the global’s value has been updated from 0 to 1, and that the first global.get has been removed: the wasm is now in a state that, when we run it in a VM, will seamlessly continue to run from the point at which wasm-ctor-eval stopped.
In this tiny example we just saved a small amount of work. How much work can be saved depends on your program. (It can help to do pure computation up front, and leave calls to imports to as late as possible.)
Note that wasm-ctor-eval‘s name is related to global constructor functions, as mentioned earlier, but there is no limitation on what you can execute here. Any export from the wasm can be executed, if its contents are suitable. For example, in Emscripten wasm-ctor-eval is even run on main() when possible.
Testing
1
./check.py
(or python check.py) will run wasm-shell, wasm-opt, etc. on the testcases in test/, and verify their outputs.
If an interpreter is provided, we run the output through it, checking for parse errors.
If tests are provided, we run exactly those. If none are provided, we run them all. To see what tests are available, run ./check.py --list-suites.
Some tests require emcc or nodejs in the path. They will not run if the tool cannot be found, and you’ll see a warning.
We have tests from upstream in tests/spec, in git submodules. Running ./check.py should update those.
Note that we are trying to gradually port the legacy wasm-opt tests to use lit and filecheck as we modify them. For passes tests that output wast, this can be done automatically with scripts/port_passes_tests_to_lit.py and for non-passes tests that output wast, see https://github.com/WebAssembly/binaryen/pull/4779 for an example of how to do a simple manual port.
Setting up dependencies
1
./third_party/setup.py [mozjs|v8|wabt|all]
(or python third_party/setup.py) installs required dependencies like the SpiderMonkey JS shell, the V8 JS shell and WABT in third_party/. Other scripts automatically pick these up when installed.
Run pip3 install -r requirements-dev.txt to get the requirements for the lit tests. Note that you need to have the location pip installs to in your $PATH (on linux, ~/.local/bin).
Fuzzing
1
./scripts/fuzz_opt.py [--binaryen-bin=build/bin]
(or python scripts/fuzz_opt.py) will run various fuzzing modes on random inputs with random passes until it finds a possible bug. See the wiki page for all the details.
Design Principles
Interned strings for names: It’s very convenient to have names on nodes, instead of just numeric indices etc. To avoid most of the performance difference between strings and numeric indices, all strings are interned, which means there is a single copy of each string in memory, string comparisons are just a pointer comparison, etc.
Allocate in arenas: Based on experience with other optimizing/transformating toolchains, it’s not worth the overhead to carefully track memory of individual nodes. Instead, we allocate all elements of a module in an arena, and the entire arena can be freed when the module is no longer needed.
FAQ
Why the weird name for the project?
“Binaryen” is a combination of binary - since WebAssembly is a binary format for the web - and Emscripten - with which it can integrate in order to compile C and C++ all the way to WebAssembly, via asm.js. Binaryen began as Emscripten’s WebAssembly processing library (wasm-emscripten).
“Binaryen” is pronounced in the same manner as “Targaryen“: bi-NAIR-ee-in. Or something like that? Anyhow, however Targaryen is correctly pronounced, they should rhyme. Aside from pronunciation, the Targaryen house words, “Fire and Blood”, have also inspired Binaryen’s: “Code and Bugs.”
Does it compile under Windows and/or Visual Studio?
Yes, it does. Here’s a step-by-step tutorial on how to compile it under Windows 10 x64 with with CMake and Visual Studio 2015. However, Visual Studio 2017 may now be required. Help would be appreciated on Windows and OS X as most of the core devs are on Linux.
# 散点数据 genPoint<-function(arg=c(),ldata){ if(length(arg)>2){ stop('The length of args is two.') } if(length(arg)<2){ arg <- c(arg,2) } #[,c(1,arg[1])] pdata <- ldata[which(ldata[,arg[2]]>ldata[,arg[1]]),] pdata <- cbind(pdata,'op'=c('Down')) #添加op列 xdata <- ldata[which(ldata[,arg[2]]<=ldata[,arg[1]]),] xdata <- cbind(xdata,'op'='UP') return(rbind(pdata,xdata)) } #以qtid分离数据,并返回一个list separateQtid<-function(pdata,qtid){ if(length(qtid)<=0){ stop('The length of qtid is at least one.') } xdata <- list() for(id in qtid){ xdata[[id]] <- pdata[which(pdata$qtid==id),] } return(xdata) } pdata<-genPoint(c(5,4),ldata) pdata <- separateQtid(pdata,qtid) #以date数据进行排序 for(id in qtid){ pdata[[id]] <- pdata[[id]][order(pdata[[id]]$date,decreasing=F),] }
这个时候pdata是一个list类型的结构,所以我只列出其中一个元素的前几行数据以展示。
1 2 3 4 5 6 7 8
> head(pdata[[1]]) qtid date close ma5 ma20 op 1002230.SZ2014-01-0248.0717.3617.28 Down 2002230.SZ2014-01-0347.0517.4117.29 Down 3002230.SZ2014-01-0645.1217.2717.29UP 4002230.SZ2014-01-0745.0817.1217.27UP 5002230.SZ2014-01-08 45.4416.9517.24UP 6002230.SZ2014-01-09 45.4216.7517.18UP
Signal<-function(ldata=c(),pdata,qtid){ if(length(qtid)<=0){ stop('The length of qtid is at least one.') } op1 <- list() for(id in qtid){ pdata[[id]] <- pdata[[id]][order(pdata[[id]]$date,decreasing=F),] op <- pdata[[id]][1,] tmp <- op$op i <- 2 nrow <- nrow(pdata[[id]]) while(i<=nrow){ if(tmp!=pdata[[id]][i,]$op){ op <- rbind(op,pdata[[id]][i,]) } tmp <- pdata[[id]][i,]$op i=i+1 } op1[[id]] <- op } return(op1) } tdata<-Signal(ldata,pdata,qtid)
同pdata一样,这也是只展示了tdata的部分。
1 2 3 4 5 6 7 8
> head(tdata[[1]]) qtid date close ma5 ma20 op 1002230.SZ2014-01-0248.0717.3617.28 Down 3002230.SZ2014-01-0645.1217.2717.29UP 10002230.SZ2014-01-1548.8017.1417.10 Down 36002230.SZ2014-02-2749.8519.1819.48UP 64002230.SZ2014-04-09 46.8216.9416.86 Down 72002230.SZ2014-04-2125.7116.8816.91UP
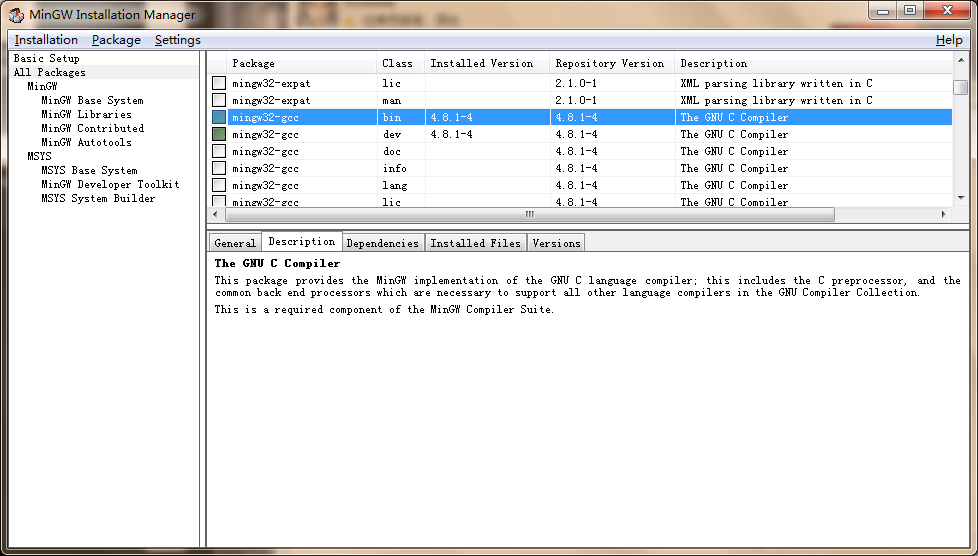
OpenCV的全称是:Open Source Computer Vision Library。OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
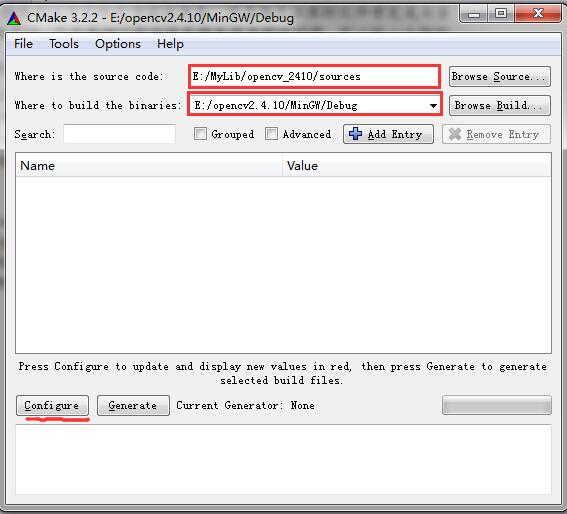
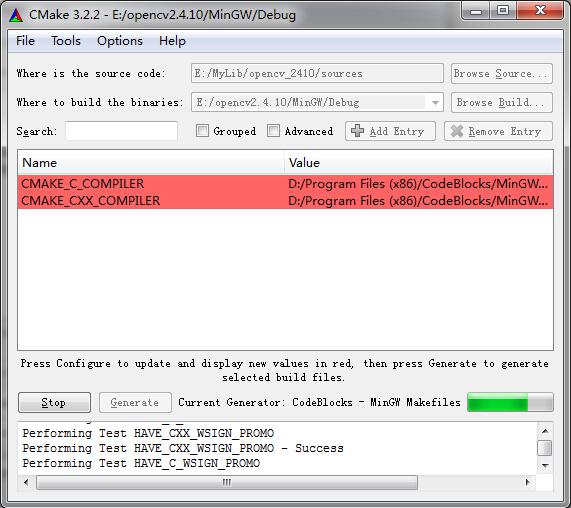
4)运行cmake,在where is the source code中填入OpenCV源代码文件的路径,比如:“…/opencv_2410/sources”;在where to build the binaries中填入编译文件需要存放的路径,比如:“…/MinGW/Debug”(存放路径文件自己定义新建一个即可)。(三点表示省略)
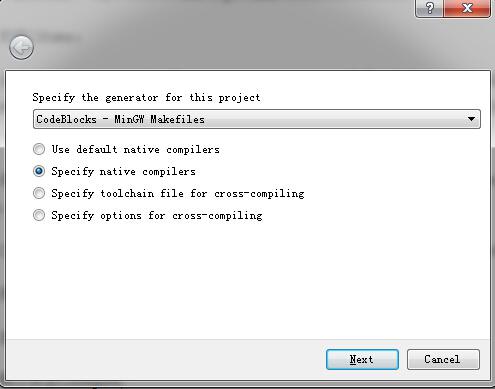
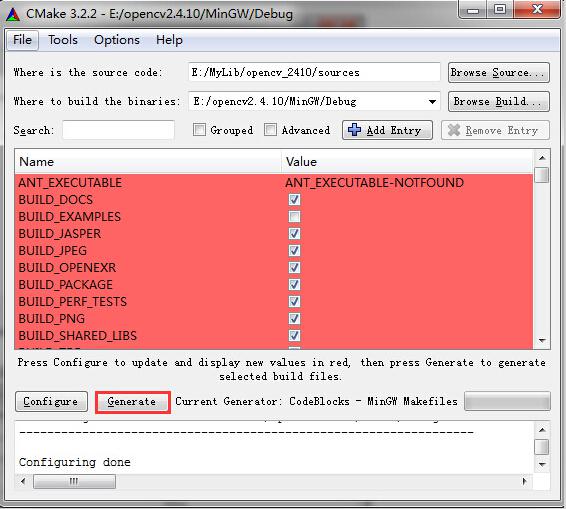
5)点击“Configure”;在Specify the generator for this project中选择MinGW Makefiles(选择刚刚安装的MinGW或者本机已有的),选中Specify native compilers,点击“Next”。
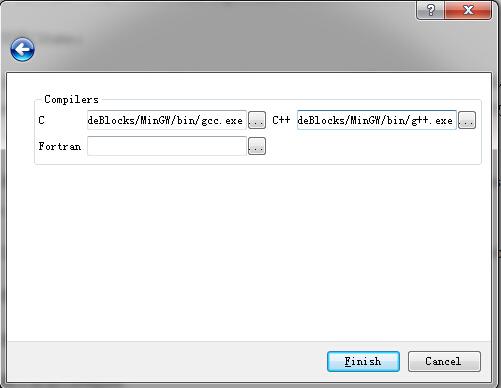
6)选择编译器路径,这里Compilers: C 选择目录为“…/MinGW/bin/gcc.exe”; C++ 选择目录为 “…/MinGw/bin/g++.exe”,点击“Finish”
This is the blog I first posted. I will make the blog more open and share something interesting sometime. I hope I can record my life by this way. And Happy New Year.God bless you.
# optimize two values to match pi and sqrt(50) evaluate <- function(string=c()) { returnVal = NA; if (length(string) == 2) { returnVal = abs(string[1]-pi) + abs(string[2]-sqrt(50)); } else { stop("Expecting a chromosome of length 2!"); } returnVal }